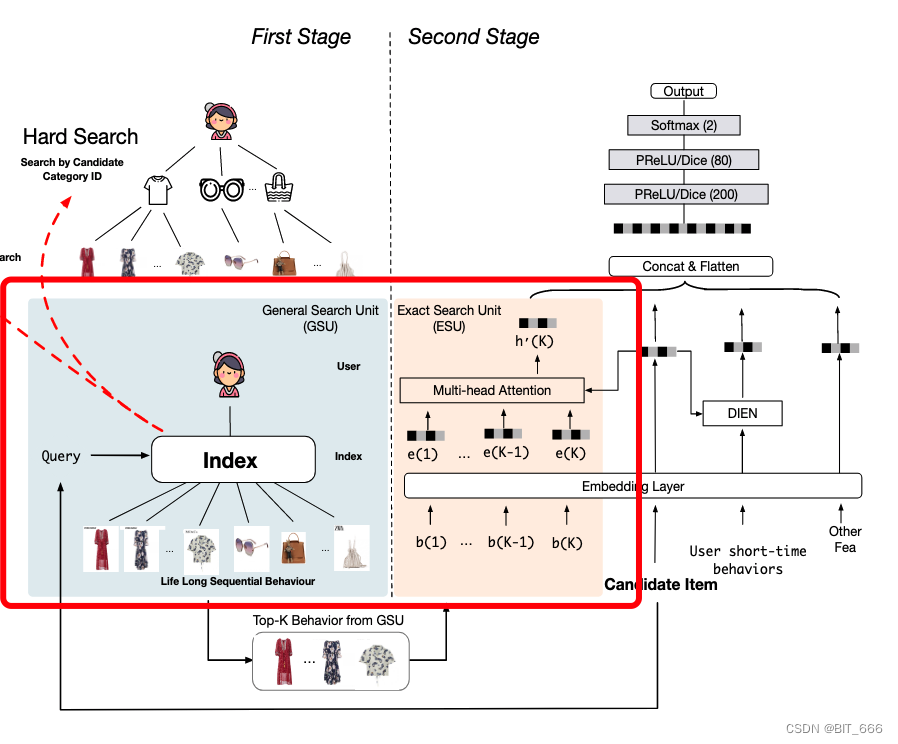
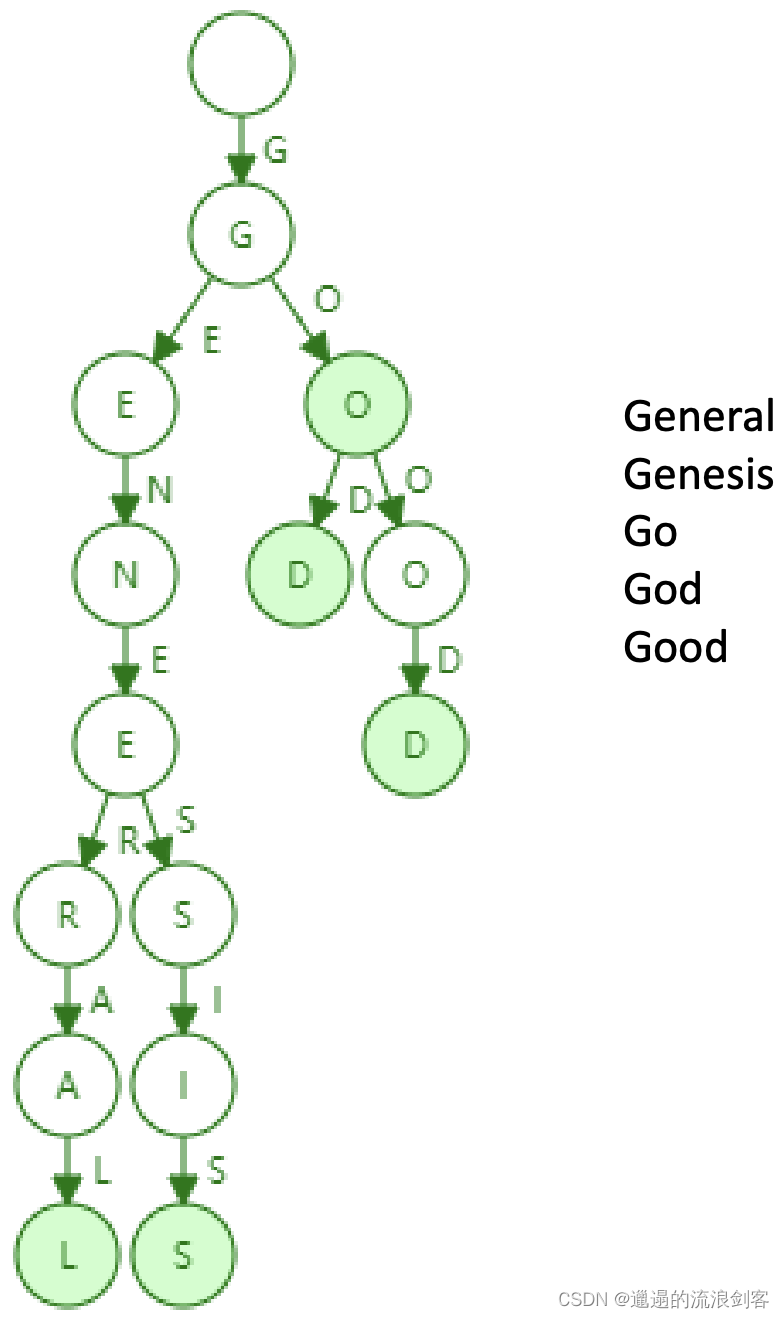
长序列用户建模 1. SIM模型模型由GSU+ESU两部分组成: 通用搜索单元GSU: 从原始的任意长顺序行为数据中进行通用搜索,结合候选项的查询信息,得到与候选项相关的子用户行为序列 精确搜索单元ESU: 模拟候选项目与 SBS 之间的精确关系 对于GSU部分,模型提出了两种通用搜索方案:硬搜索Hard Search 和 软搜索Soft Search $$ r_i = \begin{cases} Sign( 2025-06-09 #Recsys
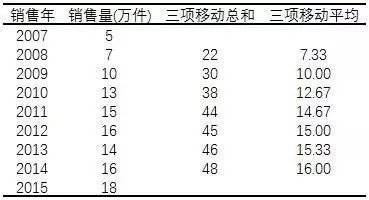
时间序列分解 1. 时间序列分解时间序列由两个组成要素构成:1、第一个要素是时间要素;2、第二个要素是数值要素。时间序列根据时间和数值性质的不同,可以分为时期时间序列和时点时间序列。 一般情况下,时间序列的数值变化规律有以下四种:长期变动趋势、季节变动规律、周期变动规律和不规则变动。 长期趋势: 长期趋势指的是统计指标在相当长的一段时间内,受到长期趋势影响因素的影响,表现出持续上升或持续下降的趋势,通常用字母T 2025-05-27 #Finance
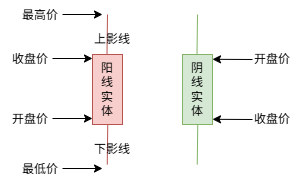
初探金融:股票市场分析 参考链接:https://xueqiu.com/4657085399/276192743? https://zhuanlan.zhihu.com/p/678399088 超买和超卖✅ 超买(Overbought)定义:资产价格在短时间内上涨过快,超过了其实际价值,存在回调或下跌的风险。 特点:1. 多头情绪过于强烈。 2. 通常表示市场短期内涨得太多、太快。 3. 可能出现价格见顶或调整的信号 2025-05-27 #Finance
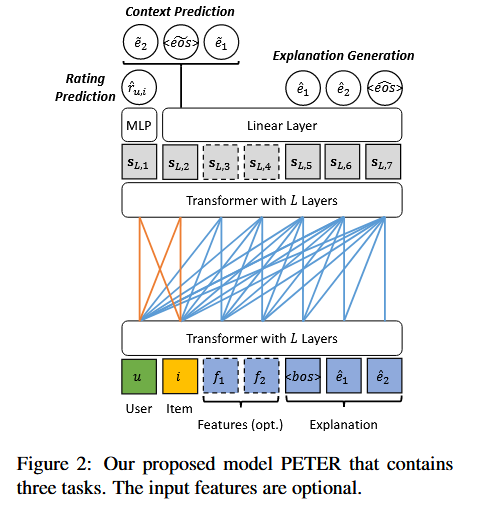
Explainable Recommendation Related Work 写在前面: 最近在肝两篇关于可解释推荐的论文,下面是写intro的过程中对related work发展脉络的一点总结 2025-05-10 #Paper #Recsys
<ETH> The DAO、反思、美链 写在前面:前段时间把b站上北大肖老师的区块链课程速通了一遍,这里引一下csdn上的优质课程笔记,便于个人后续温习。博客链接:https://blog.csdn.net/qq_40378034/category_11862943.html课程链接:https://www.bilibili.com/video/BV1Vt411X7JF/ 2025-05-01 #Web3
<ETH> 智能合约 写在前面:前段时间把b站上北大肖老师的区块链课程速通了一遍,这里引一下csdn上的优质课程笔记,便于个人后续温习。博客链接:https://blog.csdn.net/qq_40378034/category_11862943.html课程链接:https://www.bilibili.com/video/BV1Vt411X7JF/ 2025-05-01 #Web3
<ETH> GHOST、难度调整、权益证明 写在前面:前段时间把b站上北大肖老师的区块链课程速通了一遍,这里引一下csdn上的优质课程笔记,便于个人后续温习。博客链接:https://blog.csdn.net/qq_40378034/category_11862943.html课程链接:https://www.bilibili.com/video/BV1Vt411X7JF/ 2025-05-01 #Web3
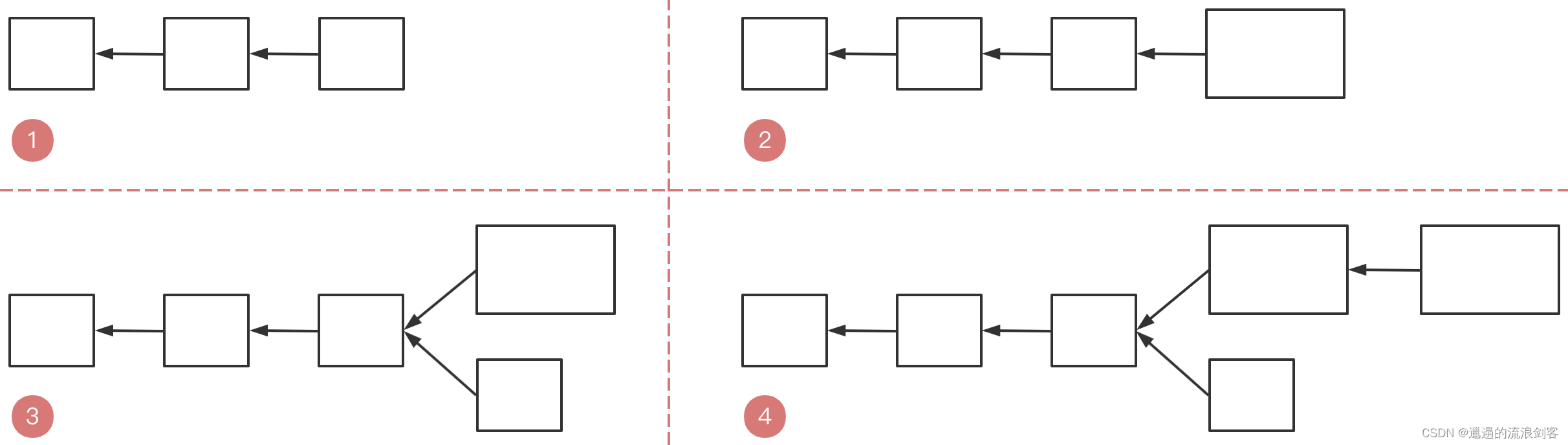
<ETH> 以太坊概述、账户、状态树&交易树&收据树 写在前面:前段时间把b站上北大肖老师的区块链课程速通了一遍,这里引一下csdn上的优质课程笔记,便于个人后续温习。博客链接:https://blog.csdn.net/qq_40378034/category_11862943.html课程链接:https://www.bilibili.com/video/BV1Vt411X7JF/ 2025-05-01 #Web3
<BTC> 分叉、匿名性 写在前面:前段时间把b站上北大肖老师的区块链课程速通了一遍,这里引一下csdn上的优质课程笔记,便于个人后续温习。博客链接:https://blog.csdn.net/qq_40378034/category_11862943.html课程链接:https://www.bilibili.com/video/BV1Vt411X7JF/ 2025-05-01 #Web3
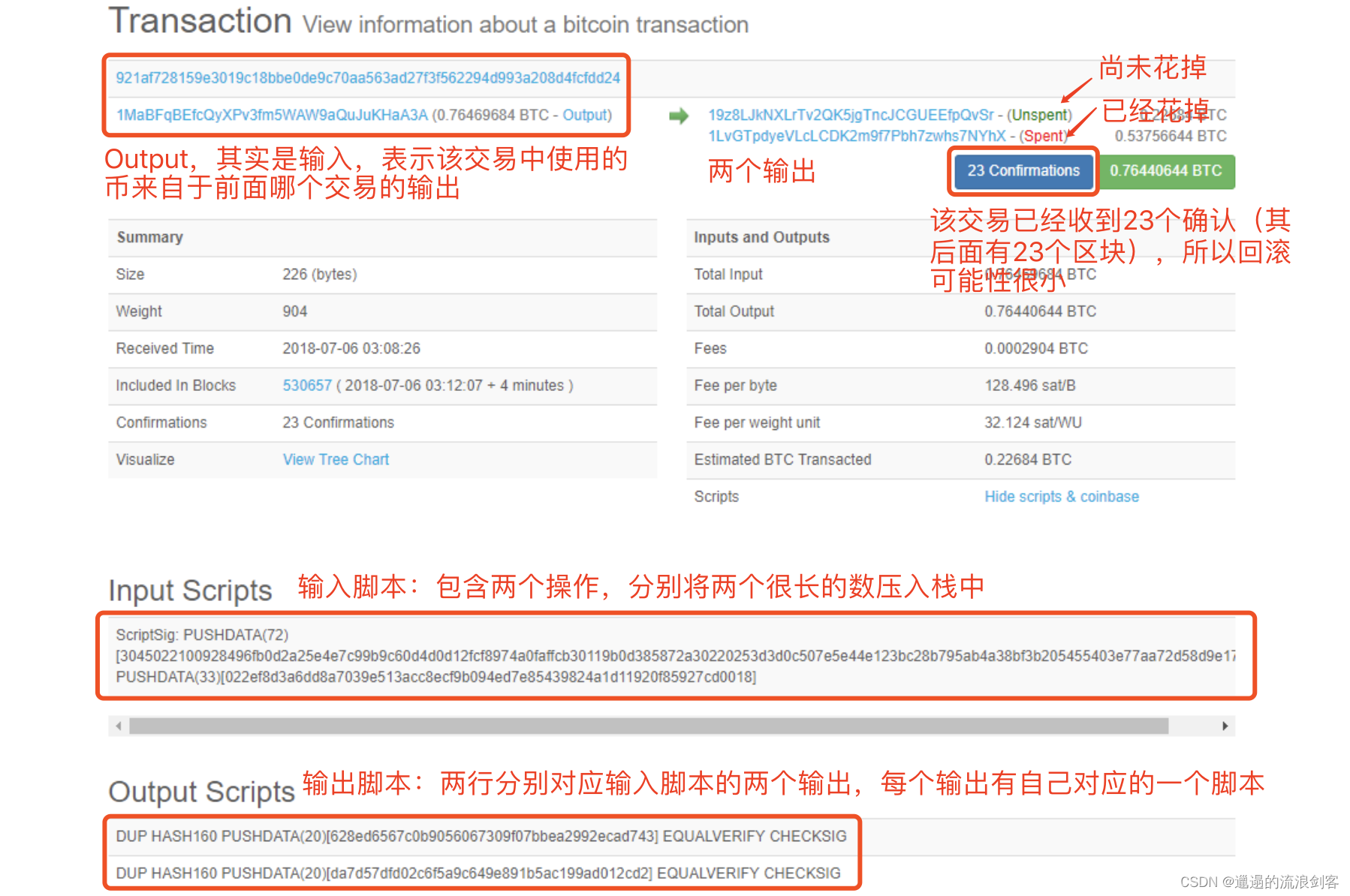
<BTC> 网络 写在前面:前段时间把b站上北大肖老师的区块链课程速通了一遍,这里引一下csdn上的优质课程笔记,便于个人后续温习。博客链接:https://blog.csdn.net/qq_40378034/category_11862943.html课程链接:https://www.bilibili.com/video/BV1Vt411X7JF/ 2025-05-01 #Web3