关于模型padding左对齐和右对齐的问题
最近微调模型进行原因预测任务训练的时候,在eval阶段进行推理生成时遇到了一个警告:“A decoder-only architecture is being used, but right-padding was detected! For correct generation results, please set padding_side='left' when initializing the tokenizer.”,我将tokenizer初始化的定义设置为左填充依然出现该警告,问了下身边对大模型比较了解的同学,发现是token序列结尾加了eos符号导致出现的warning,下面是transformers库中该警告出现的条件:
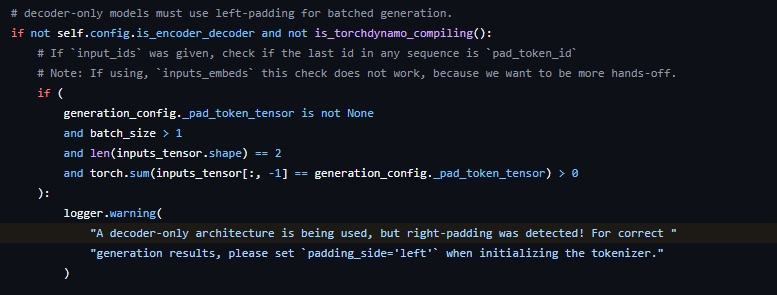
为什么模型训练选择右填充,推理时选择左填充;为什么训练时需要在结尾添加
训练:Q+A[EOS]
模型训练时,对于输入的token序列,我们知道其真实标签(Ques部分可直接用-100作为 mask 填充或无效标签,以确保这些位置不会影响损失计算),采用右填充是为了让每个batch内的样本长度对齐。在结尾添加eos标记符是为了告诉模型输入序列的结束位置,如果没有 EOS token,模型可能会将序列当作是没有结束的,进而可能会试图无限制地生成下一个 token,导致训练不稳定或生成行为不正确
推理:Q
自回归模型在推理时,从bos标记符开始从左到右依次预测下一个词来生成内容,如下面的图所示:
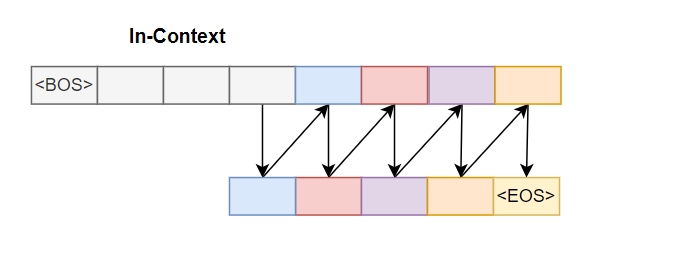
如果采用右填充,