Graph + RAG
Graph + RAG
图RAG相比于传统RAG的优势:
- 多跳推理能力 2. 关系建模能力 3. 高效的知识更新与管理 4. 减少检索的噪声和生成的幻觉
最近看了几篇图RAG的论文:
G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering(https://arxiv.org/pdf/2402.07630)
Motivation: 引入文本图进行检索增强
开源代码:https://github.com/XiaoxinHe/G-Retriever
首先根据已有的外部知识构建知识图谱,并对每个节点和关系,利用其固有的文本属性进行特征编码。针对用户的query,进行相似度检索,得到节点和边的topk子集。然后设计了一种强化学习策略基于检索得到的子集构建subgraph。在生成阶段,LLM的参数被冻结,除了用户的query以外,还有检索子图的文本属性所构成的hard prompt和基于可训练graph encoder得到的soft prompt 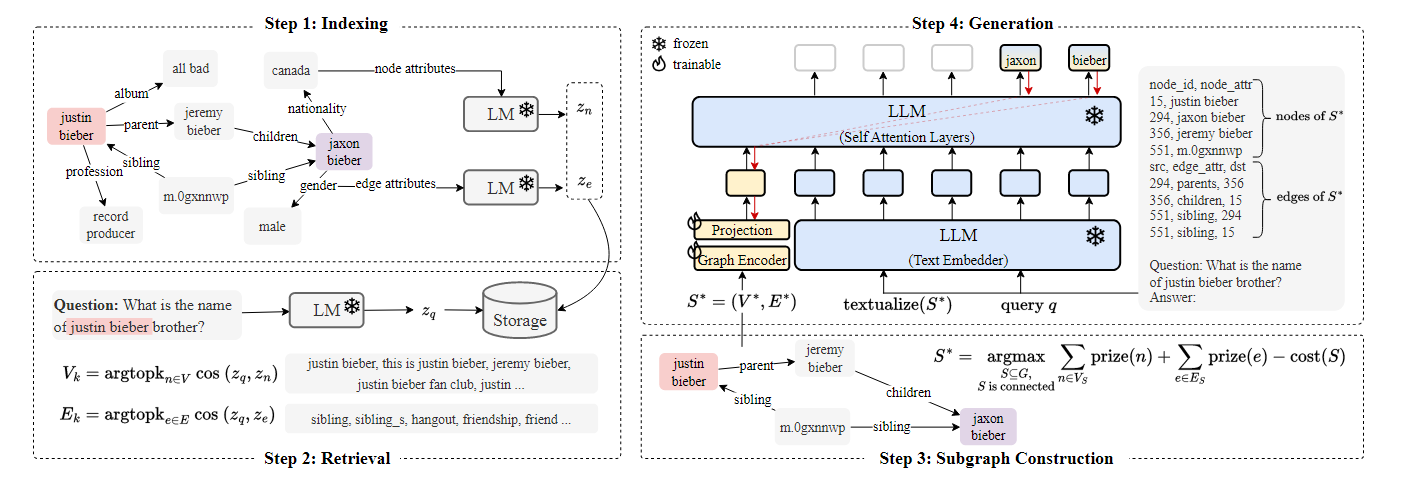
Knowledge Graph Retrieval-Augmented Generation For LLM-Based Recommendation(https://arxiv.org/pdf/2501.02226)
Motivation: 传统的RAG方法忽视了知识的结构关系,借助外部知识构建KG,对推荐进行检索增强;
检索阶段,首先训练一个GNN网络用来对item-entity知识图谱的每个节点和关系进行编码,并以每个节点作为中心节点生成的多跳特征表示收集起来,构建向量数据库。对于待预测的用户节点,根据其交互历史中的每个节点,利用其文本特征从KG VecDB中检索相关子图,并对检索得到的所有子图进行重排序用于构建soft prompt,从而增强LLM的推荐能力。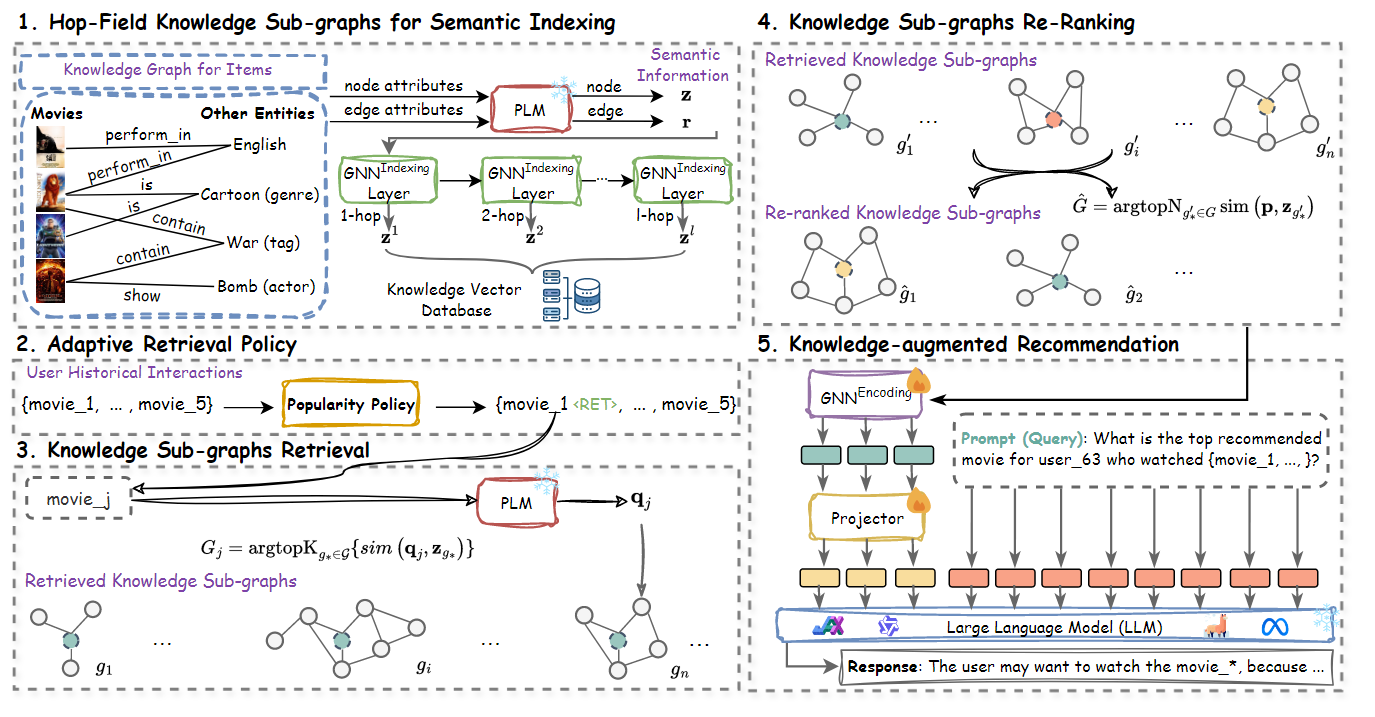
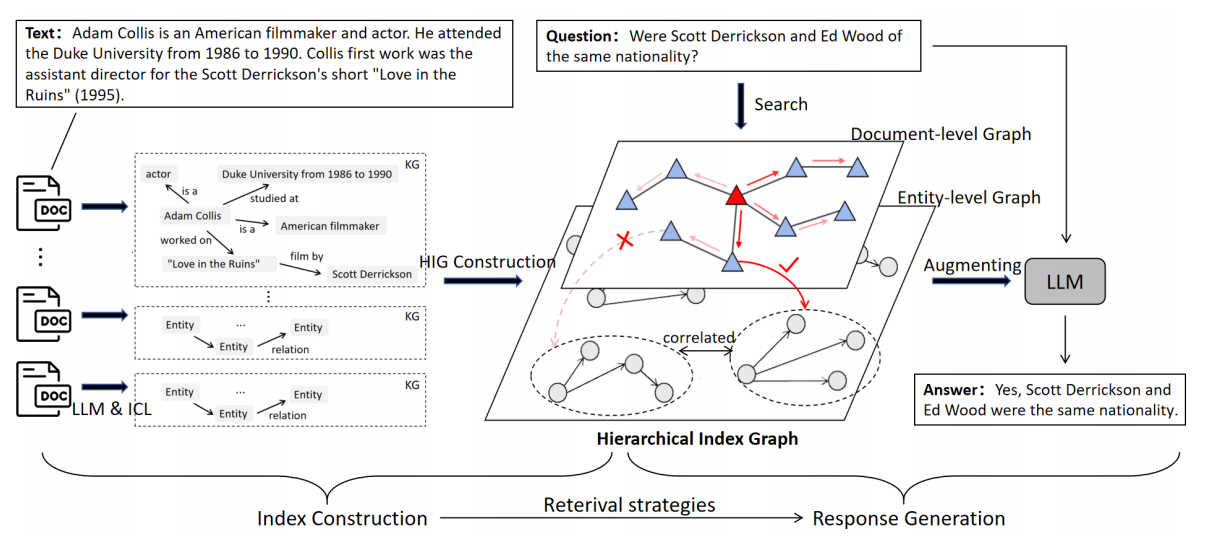
KG-Retriever: Efficient Knowledge Indexing for Retrieval-Augmented Large Language Models(https://arxiv.org/pdf/2412.05547)
Motivation: 对结构信息分层检索,从根本上缓解信息碎片化的问题
设计了Doc层(Document-level Graph)和KG层(Entity-level Graph)分别用于建立文档内和文档间的连接,Doc Graph的构建是对每个文档进行文本编码,并基于语义相似性获得每个节点的K近邻居;KG Graph的构建是对每个文档进行信息抽取,从而获得对应的知识图谱。检索策略上,作者考虑了两级检索:文档级检索和实体级检索,前者除了考虑用户查询和每个文档的语义相似性以外,还根据Doc Graph获取这些topN文档的one-hop邻居;后者则针对上一阶段检索的所有文档所对应的kg图检索语义相关的实体集,和query一起作为最终LLM的输入