GraphRAG综述
Sec.1 传统RAG系统面临的挑战
复杂的查询理解:传统的 RAG 方法依赖于简单的关键字匹配和向量相似性技术,不足以捕捉准确和全面所需的深层语义细微差别和多步骤推理过程。例如,当询问概念 A 和概念 D 之间的联系时,这些系统通常只检索直接相关的信息,而错过了像 B 和 C 这样可以弥合关系的关键中间概念。这种狭窄的检索范围限制了 RAG 的能力,使其无法进行广泛的上下文理解和复杂的推理
集成来自分布式源的领域知识:检索到的知识通常是扁平的、广泛的和错综复杂的,而领域概念通常分散在多个文档中,不同概念之间没有明确的层次结构关系。尽管 RAG 系统试图通过将文档划分为较小的块以实现有效和高效的索引来管理这种复杂性,但这种方法无意中牺牲了关键的上下文信息,严重损害了检索准确性和上下文理解。这种限制阻碍了在相关知识点之间建立强大联系的能力,导致理解碎片化,并降低利用特定领域专业知识的效率。
LLM的固有约束:受到其固定上下文窗口的限制,LLM无法完全捕获复杂文档中的长距离依赖关系。在专业领域中,在广泛的知识背景下保持连贯性的挑战变得越来越棘手,因为关键信息可能会在上下文窗口截断期间丢失。
系统效率和可拓展性:RAG 系统在计算上可能既昂贵又耗时 ,尤其是在处理大规模知识源时,因为模型需要搜索大量非结构化文本以查找相关信息。此外,实时检索和跨文档推理可能会带来相当大的延迟,从而对用户体验产生负面影响。此外,实时检索和跨文档推理可能会带来相当大的延迟,从而对用户体验产生负面影响,从而限制了它在广泛和动态的专业环境中的实际部署
Sec.2 现有的GraphRAG分类
基于知识的GraphRAG: 它使用图作为知识载体,专注于将非结构化文本文档转换为显式和结构化的 KG,其中node代表领域概念,edge捕获它们之间的语义关系,从而更好地表示分层关系和复杂的知识依赖关系
基于索引的GraphRAG: 使用图作为索引工具从语料库中检索相关的原始文本,它保留了原始文本形式,同时主要将图形结构用作索引机制来有效地组织和检索相关文本块。通过将图形结构合并到文本索引中,基于索引的 GraphRAG 方法在文本块之间建立语义连接,以实现高效的查找作和检索
基于知识的 GraphRAG 旨在通过基于图的推理能力创建结构化的知识表示,以便更好地理解复杂的关系;而基于索引的 GraphRAG 则侧重于通过基于图的索引策略优化相关文本信息的检索和可访问性
Sec.3 Overview the Framework of RAG
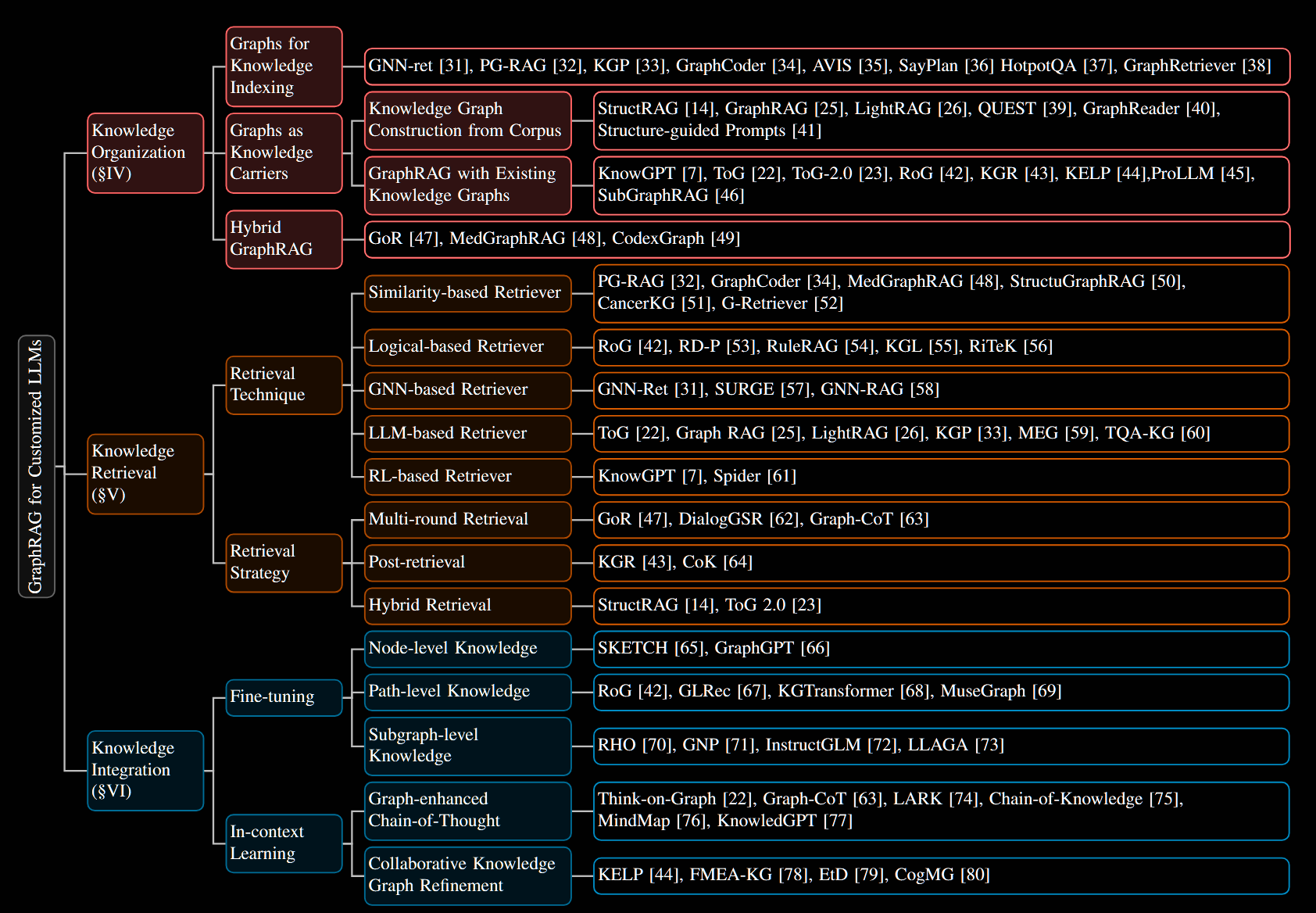
RAG框架主要由三个部分组成,Knowledge Organization,Knowledge Retrieval,Knowledge Integration。下图展示了传统RAG、基于知识的GraphRAG和基于索引的GraphRAG在这三部分的各自实现方式。
Knowledge Organization: 该部分关注外部知识库的构建
传统RAG:传统RAG主要采用将大规模文本语料库拆分为可管理块的策略,然后使用嵌入模型将这些块转换为嵌入,其中嵌入用作向量数据库中原始文本块的键。此设置通过在语义空间中基于距离的搜索实现高效的查找作和检索相关内容。常见的优化方法:粒度优化和索引优化。
GraphRAG: 基于图的方法构建外部信息,通过显式知识表示(作为知识载体的图)或索引机制(用于知识索引的图)。这些方法可实现高效的上下文感知信息检索。
Knowledge Retrieval: 该部分关注如何更精准高效的进行检索
传统RAG: 常涉及的检索方法:KNN、TF-IDF、BM25。为了提高检索的准确性和效率,一方面可以在检索前通过优化表示或重排序等技术来提高检索模型的准确性,例如GAR、EAR等;另一方面,对检索模型进行训练,例如Replug,Atlas,Flare等。
GraphRAG: GraphRAG 模型使用基于图的规划器(可学习的规划器或基于图算法的规划器)根据输入查询检索相关信息。这些检索技术不仅考虑了查询和每个文本块之间的语义相似性,还考虑了查询类型和检索到的子图之间的逻辑连贯性
Knowledge Integration: 该部分关注如何将检索结果和用户查询高质量整合
传统RAG:提高检索到的内容的质量:强化学习方法LeanContext LLM自评估方法Self-RAG 评估检索内容重要性。此外,考虑到对大量检索到的段落进行编码是资源密集型的,这会导致大量的计算和内存开销,相关优化方法:RAGCache TCRA-LLM
GraphRAG: 一旦检索到相关知识,GraphRAG 模型就会将其与用户查询整合起来作为LLM input。集成过程的目标是将检索到的知识无缝合并到生成的文本中,从而提高其质量和信息量。一个关键的设计考虑因素是,如何在最终的基于文本的提示中保留检索到的子图信息的丰富性,而不会引入冗余或错误地强调文本描述中不太关键的方面
Sec.4 Knowledge Organization in GraphRAG
首先构建一个图结构来组织知识,然后检索和集成与查询相关的信息。下面对Sec.2 提到的范式展开具体介绍。
Graphs for Knowledge Indexing
基于索引的 GraphRAG 方法利用图结构来索引和检索相关的原始文本块,然后将其馈送到 LLM 中以进行知识注入和上下文理解。这些索引图应用语义相似性或特定于域的关系等原则来有效地桥接单独文本段落之间的连接。与仅将图用作知识载体相比,这种技术通过直接总结与查询相关的原始文本块中的信息来提供更丰富的答案。
面临的挑战:(1) 简洁性和相关性:确保构建的图仅捕获相关关系,而不会因不必要的连接而过载,这是一项重大挑战,从而有助于有效调用相关文本块而不会产生冗余 (2)一致性和冲突解决:不同的数据块可能会引入冲突的信息。解决这些冲突并确保图保持一致、可靠和结构良好至关重要。
Graphs for Knowledge Carriers
优势:1)高效检索与查询相关的知识 2)长跨度的连贯多步推理
局限性:(1) 缺乏高质量的 KG:对于直接使用KG作为外部知识库,这一研究方向受到高质量KG可用性的限制。构建KG是资源密集型的,但大多数公开可用的KG仍然远非全面(2) 效率和有效性之间的权衡:当从文本语料库构建 KG 时,提取知识的粒度在平衡效率和有效性方面起着至关重要的作用。保留细粒度信息会导致更大、更详细的 KG,这可能会阻碍计算效率。相反,紧凑的 KG 可能会牺牲重要的细节,从而导致潜在的信息丢失。
Sec.5 Knowledge Retrieval Process
基于图的知识检索一般分为Preprocess/Matching/Pruning三个步骤,如下图所示:
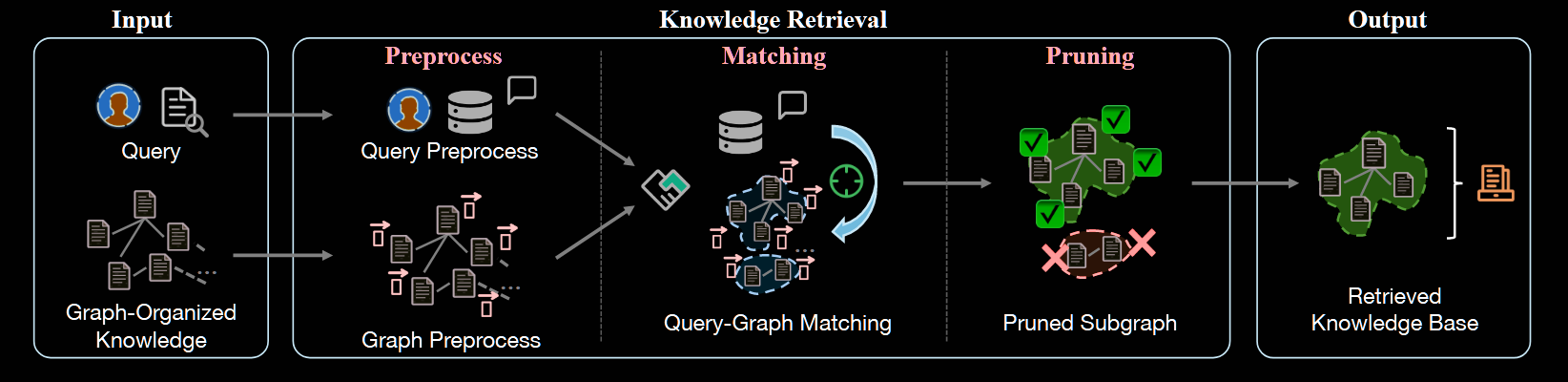
Query/Graph Preprocess 预处理阶段同时对查询数据库和图形数据库运行,以便为高效检索做好准备。对于查询预处理,系统通过矢量化或关键术语提取将输入问题转换为结构化表示。这些表示形式用作后续检索作的搜索索引。在图方面,图数据库经过更全面的处理,其中预训练的语言模型将图元素(实体、关系和三元组)转换为密集的向量表示,作为检索锚点 。此外,一些高级检索模型在图数据库上应用图神经网络 (GNN) 来提取高级结构特征,而一些方法甚至采用规则挖掘算法生成规则库,作为图知识的丰富、可搜索的索引
Matching 匹配阶段在预处理的查询和索引图数据库之间建立连接。此过程将查询表示形式与图索引进行比较,以识别相关的知识片段。匹配算法同时考虑图中的语义相似性和结构关系。根据匹配分数,系统检索与查询高度相关的连通组件和子图,从而创建一组初始的候选知识。
Knowledge Pruning 修剪阶段会优化最初检索的知识,以提高其质量和相关性。此优化过程解决了检索过多或不相关信息的常见挑战,尤其是在处理复杂查询或大型图数据库时。剪枝算法应用一系列细化作来整合和总结检索到的知识。具体来说,系统首先删除明显不相关或嘈杂的信息。然后,它整合了相关的知识片段,并生成了复杂图知识的简明摘要。通过提供精炼和重点突出的摘要,LLM 能够更好地理解信息的上下文和细微差别,从而做出更准确和有意义的回答。
Sec.6 Knowledge Retrieval Techniques
基于语义相似性的检索器 通过测量离散语言空间或连续向量空间中的查询与知识库之间的相似性来进行适当的答案检索 (1)离散空间建模。离散空间建模方法主要利用语言离散统计知识直接对文本字符串进行建模。例如子字符串匹配、正则表达式和精确短语匹配等算法 (2)嵌入空间建模。利用预训练语言模型和词嵌入等方法,例如 TF-IDF、Word2Vec 和 GloVe
基于逻辑推理的检索器 采用符号推理从图知识库中推断和提取相关信息。此方法包括创建逻辑规则和约束,以阐明知识库固有的关系和层次结构,例如 规则挖掘 、归纳逻辑编程 和 约束满足 等技术
基于 GNN 的 Retriever 主要利用图神经网络对构建的图库中的节点进行编码。检索主要依赖于同时包含情感意义和结构关系理解的节点表征的编码相似性。基于 GNN 的检索器需要训练 GNN 编码器。此外,由于缺乏明确标注的数据,训练的重点是设计一个合适的损失函数,使 GNN 能够学习通过表示编码准确定位目标知识
基于 LLM 的检索器 关于构建的图库,基于 LLM 的知识检索器主要侧重于利用 LLM 来理解图并识别关键子图。
基于强化学习的检索器 强化学习 为 GraphRAG 系统中的检索提供了一种自适应和动态策略。通过将检索过程构建为顺序决策挑战,基于 RL 的方法使代理能够在环境反馈的指导下学习和遍历图库,以寻找最相关的信息。
这种方法赋予系统通过主动交互和积累经验不断提高其检索性能的能力。这个过程可以描述如下:相关的推理背景在于一个特定于问题的子图 $G_{sub}$,其中包含所有源实体 $Q_s$、目标实体 $Q_t$ 及其邻居。理想的子图 $G_{sub}$ 应具有以下属性:(i) $G_{sub}$ 包含尽可能多的源实体和目标实体;(ii) $G_{sub}$ 中的实体和关系与问题上下文具有很强的相关性;(iii) $G_{sub}$ 简洁明了,几乎没有冗余信息,因此可以输入到长度有限的 LLM 中。相关方法:Deep QNetworks, Policy Gradients, and Actor-Critic
Sec.7 Knowledge Integration
微调技术:利用各种图形信息的微调过程可以根据输入目标的粒度分为三个不同的类别:(i) 节点级知识:关注图形中的各个节点。(ii) 路径级知识:专注于节点之间的连接和序列。(iii) 子图级知识:考虑由多个节点组成的较大结构及其互连。我们将详细探讨这些方面中的每一个。
使用 Node 级知识进行微调。在许多基于图的 RAG 系统中,每个节点都链接到一个文档,例如引文网络中的摘要。由于特定领域的数据很少出现在预训练语料库中,因此一些研究在进行下游任务微调之前采用指令调优来加强对特定领域的知识理解。一种简单的微调方法包括将节点和相邻文本作为上下文信息馈送到 LLM 中,以帮助预测 1、2、3。鉴于检索到的文档可能很广泛,研究人员可以利用 LLM 将这些文本提炼成单个嵌入 4。尽管缺乏词汇外标记的预训练数据,但 LLM 能够在实践中识别这些嵌入中的信息。
使用 Path-level Knowledge 进行微调。语言任务通常涉及复杂的推理,需要对事实关系有清晰的理解。利用知识图谱路径,LLM 通过关系和实体的引导增强自身推理能力。这些路径可以是从问题实体到答案实体的最直接路线,也可以使用 图检索模型 或 启发式方法 进行挖掘。它们可以用作输入和输出,但是当两个节点之间存在多条路径时,过滤掉嘈杂的路径同时保留知识图谱中的关系至关重要。为了保持实体表示的完整性及其沿路径的关系,一些方法侧重于将这些路径作为训练目标,预测两个节点之间路径上的节点和关系5,甚至跨多个路径6。这使 LLM 能够进行Path级推理并产生可靠的输出。
使用 Subgraph 级知识进行微调。与路径数据的线性拓扑不同,子图数据表现出更复杂、更不规则的拓扑。一种简单的方法是使用图编码器将子图级信息压缩到读出嵌入中。或者,将图数据转换为序列。然而,这些方法往往忽略了子图中丰富的文本内容,无法使 LLM 认识到底层的图结构。为了解决这个问题,一些工作专注于调整 transformer 架构以更好地处理结构化数据,例如7、8,而另一些则将节点和边的描述直接合并到提示中,例如9、10。然而,现有方法仍然存在挑战。前者可能会因架构更改而丢失在预训练期间获得的知识,而后者可能难以处理具有大量节点和边的密集图。
相关工作总结
参考文献:https://arxiv.org/pdf/2501.13958