命名实体识别&关系抽取 小结
BIO标记法
B-(Begin):表示一个实体的开始(首个 token)。
I-(Inside):表示实体的内部(除首个 token 以外的部分)。
O-(Outside):表示非实体的 token。
例如:**”Apple Inc. is based in California.”
BIO 标注:
| Token | BIO 标签 |
|---|---|
| Apple | B-ORG |
| Inc. | I-ORG |
| is | O |
| based | O |
| in | O |
| California | B-LOC |
| . | O |
常见的实体类别
| 实体类别 | 含义 |
|---|---|
| PER (Person) | 人名(例如:Elon Musk, Bill Gates) |
| ORG (Organization) | 组织名(例如:Apple, Google, NASA) |
| LOC (Location) | 地名(例如:California, Beijing, Paris) |
| MISC (Miscellaneous) | 其他(例如:品牌名、事件名等) |
在 NER 任务 中,BIO 标签常作为序列标注模型(如 BiLSTM-CRF、Transformer)训练的目标
训练模型
- 输入:Word Embeddings(如 BERT, GloVe)
- 模型:BiLSTM + CRF / Transformer
- 输出:BIO 标注序列
预测新文本
输入新文本后,模型预测对应的 BIO 标签,从而提取实体。
RE(Relation Extraction)训练集
spo: subject-predicate-object 头实体-关系-尾实体
训练集中的Predicate列表
{
“O”: 0,
“I”: 1,
“注册资本”: 2,
“作者”: 3,
“所属专辑”: 4,
“歌手”: 5,
…
“上映时间_@value”: 8,
“上映时间_@area”: 9,
…
}
对于同一个S-P,句子中是可能存在多个不同的合法O的,那我们就需要使用两个或多个不同的S-P来对应这些不同的O。一种最常见的方法就是对P再进行细分。如上面示例中的“上映时间_@value”和”上映时间_@area“
训练集中的spo列表
{
“predicate”: [“empty”, “empty”, “注册资本”, “作者”, “所属专辑”, …],
“subject_type”: [“empty”, “empty”, “企业”, “图书作品”, “歌曲”, …],
“object_type”: [“empty”, “empty”, “Number”, “人物”, “音乐专辑”, …]
}
前两个empty是为了O和I标签留的,因为之前定义的predicate列表中的前2个标签分别为O、I,这两个标签不会起到连接首尾实体的作用,因此需要置为empty。
NER模型的训练原理
将实体抽取问题转化为Token Classfication问题。
Ques:如何实现关系抽取?
Ans:在字符类别中添加入「关系标签」,即该字符是否能和这句话当中的其他字符产生关联关系。
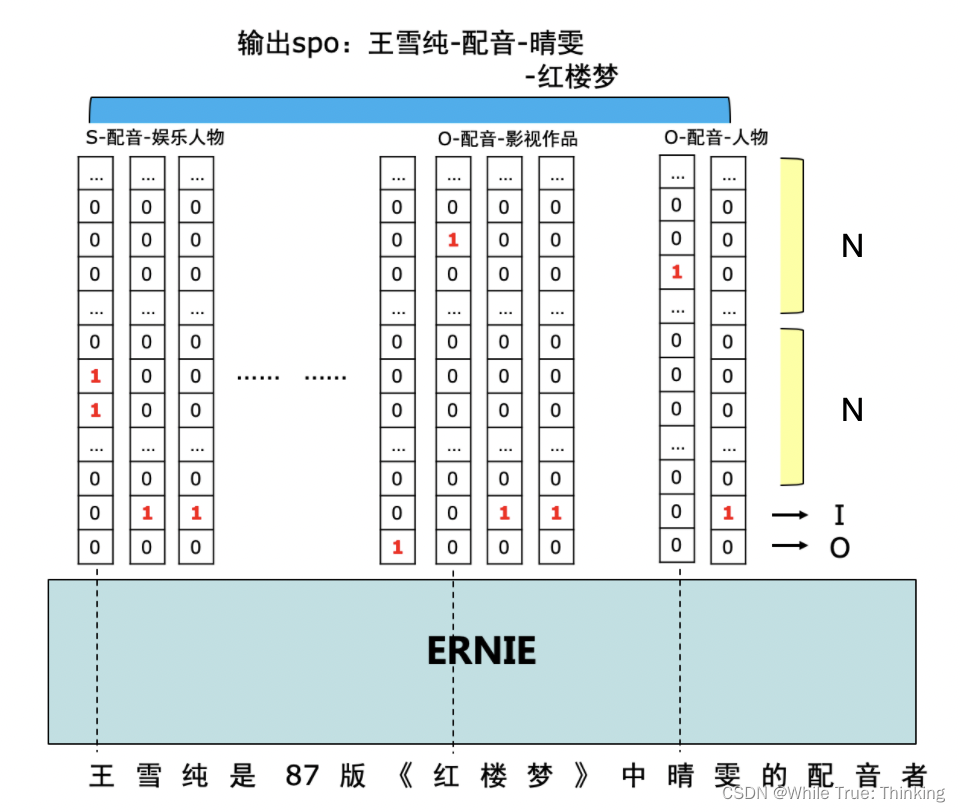
对每个token,label一共有(2N + 2)维,其中 N 为 Predicate 的类别个数
损失函数一般使用BCE Loss