Explainable Recommendation Related Work
写在前面: 最近在肝两篇关于可解释推荐的论文,下面是写intro的过程中对related work发展脉络的一点总结
Neural Rating Regression with Abstractive Tips Generation for Recommendation (NRT)
(使用GRU架构进行多任务可解释推荐)
除了预测给定用户和目标的评级以外,模型还可以简洁的句子自动解释为tips(这里的Tips类似于Explanation,作者将其描述为“比评论更简洁,只需几句话就可以解释用户体验、感受和建议”)
对于Tips的生成,作者采用GRU将user和item的潜在特征表示“翻译”为一个简洁的句子;对于评分预测,作者采用多层感知器将user和item的潜在特征表示映射到评分中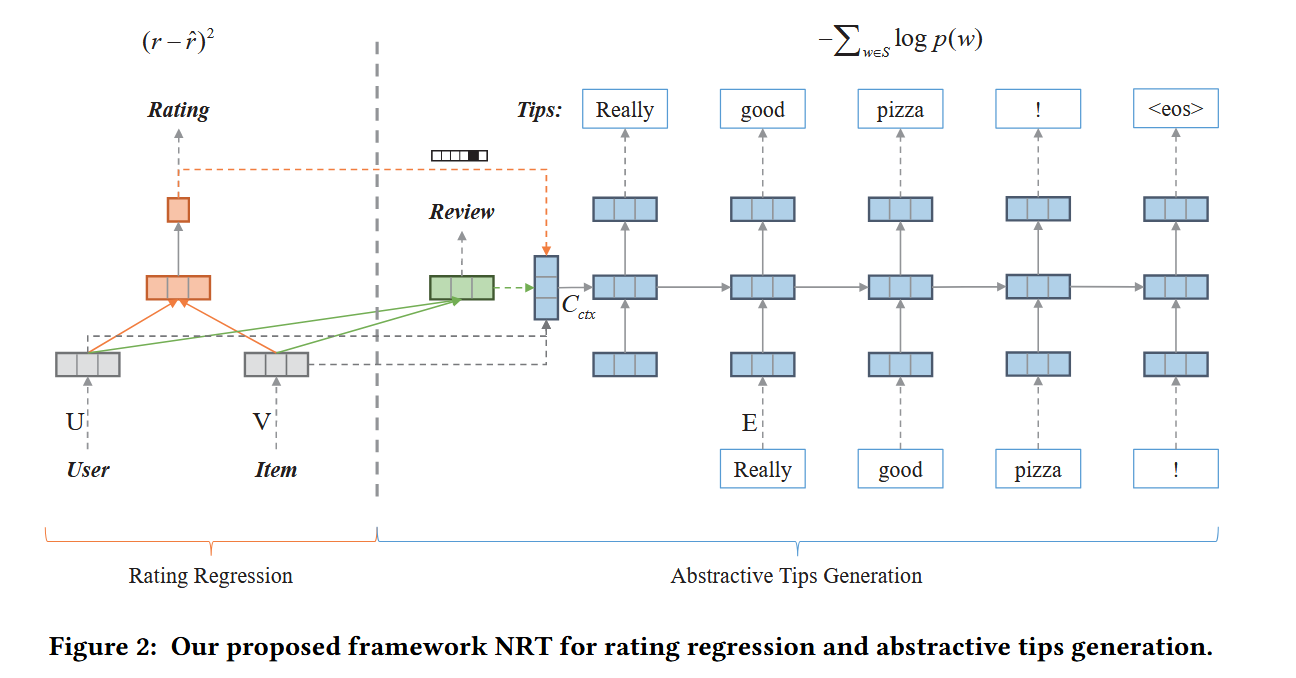
Learning to Generate Product Reviews from Attributes (Att2Seq)
(使用LSTM架构进行多任务可解释推荐)
作者提出了一种注意力增强的属性到序列模型,用于为给定的属性信息生成解释。属性编码器学习将输入属性表示为向量,序列解码器通过根据这些向量调节其输出来生成评论。此外,作者还引入了一个注意力层,注意力机制学习生成的单词和属性之间的软对齐,并自适应地计算用于预测下一个标记的编码器端上下文向量。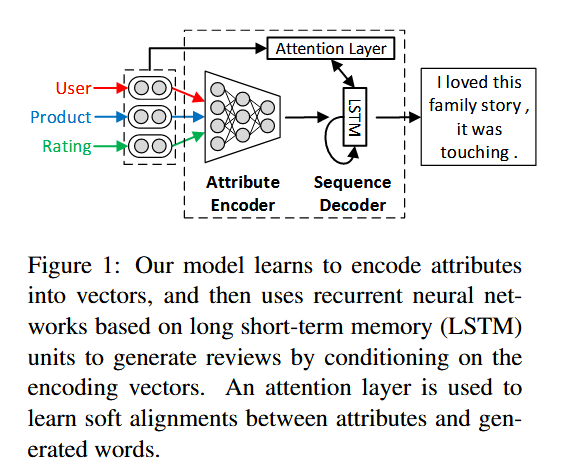
下面是关于注意力机制的工作机理: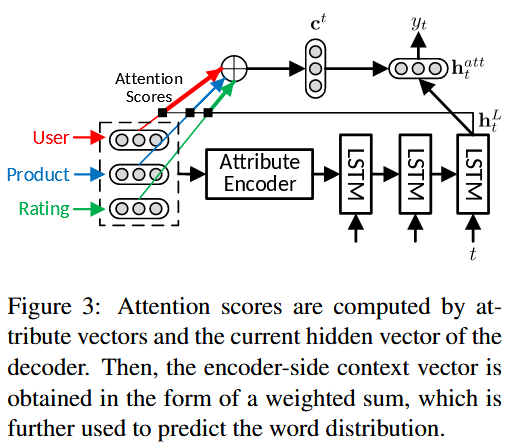
Personalized Transformer for Explainable Recommendation (PETER)
(使用Transformer架构进行多任务可解释推荐)
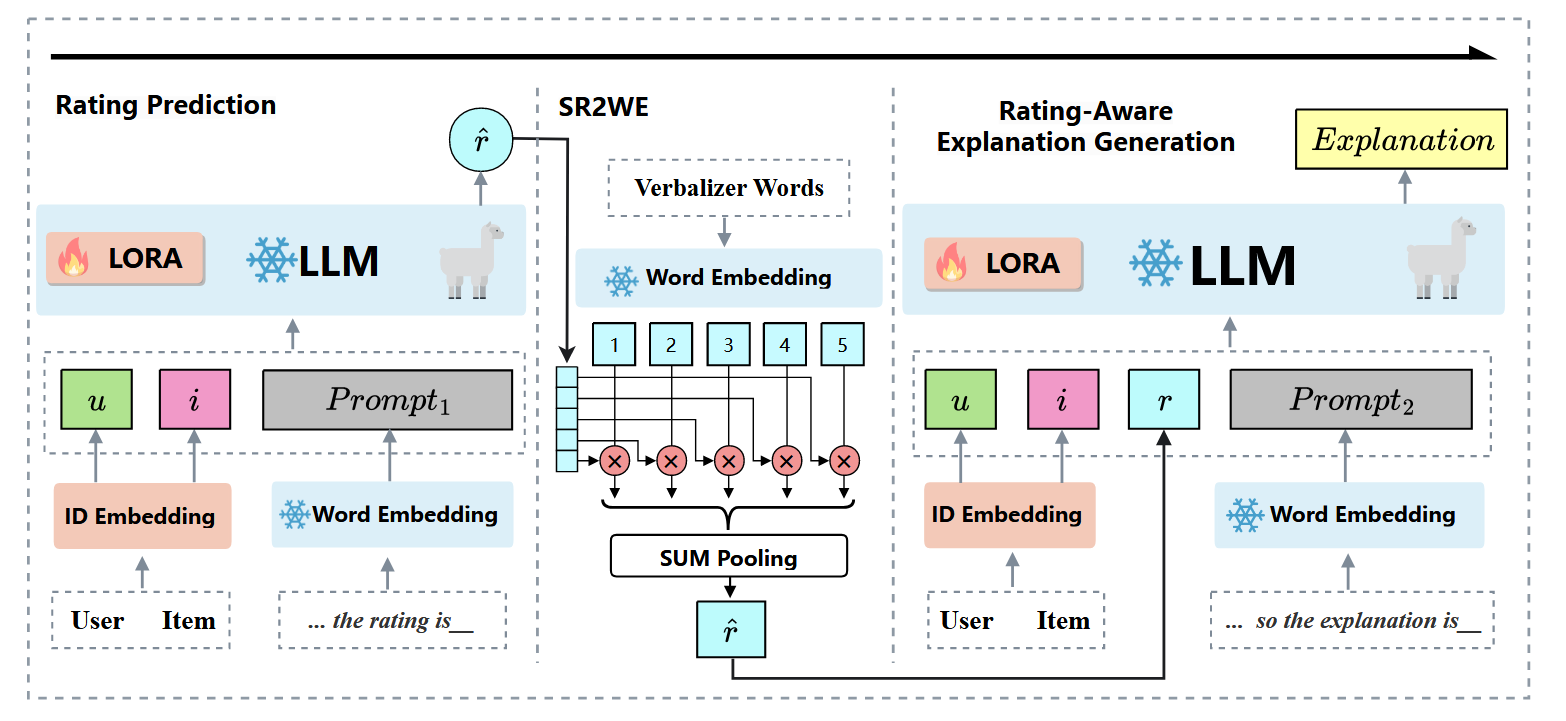
解决的问题:使用用户和商品ID进行个性化推荐,但是Transformer建模时无法理解该ID所蕴含的语义。论文提出了一个可解释推荐框架PETER,利用ID来预测目标解释的单词
传统的基于Transformer的ID建模是将ID视为单词,但是ID的出现频率远低于单词,导致模型对ID不敏感,当为用户-商品生成解释的时候,Transformer的Attention-Map更关注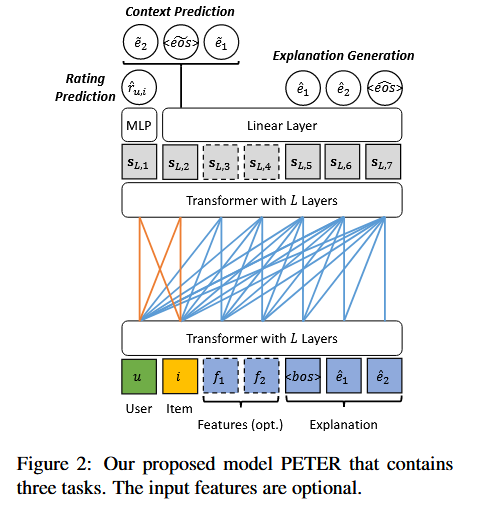
关于ID的OOV问题,作者没有将海量的ID放入词表当中,而是对每个ID执行embedding lookup。此外,作者更改了Transformer的Attention Mask Metrics, 让uid token和iid token可以互相关注,这在上下文预测和推荐任务中会使用到
总结:
Att2Seq 和 NRT 采用注意力机制和递归神经网络(RNN)来生成文本解释。最近的进展进一步探索了Transformer在文本生成中的利用,为推荐结果提供了有价值的见解。然而,这些方法面临着一个共同的挑战,即解释数据的可用性有限,这阻碍了它们生成高质量解释的能力。同样重要的是要强调,基于ID的方法严重依赖ID嵌入,导致泛化能力有限,并且在适应冷启动推荐场景中新增加的用户和项目时存在困难。
在主干模型的演化上,随着自然语言生成技术的进步,一些研究采用了递归神经网络、门控递归单元、未预训练的 Transformer 和预训练的语言模型 来生成解释。预训练的大型语言模型最初在 PEPLER 中引入,以提高解释生成的性能。尽管 PEPLER 通过 GPT-2 利用基于提示的迁移学习,但它无法以适合指令调整的方式构建训练数据,从而限制了系统产生高质量解释的能力。
评分-解释一致性推荐的相关工作:
The Problem of Coherence in Natural Language Explanations of Recommendations (CER)
Challenge:生成的文本和预测评级之间的连贯性是解释有用的必要条件。目前可解释推荐的方法主要基于深度神经模型,相比于早期基于预定义句子模板的方法可以产生更丰富、更流畅的文本解释。然而,这些方法主要考虑如何提高生成的文本质量,却忽视了文本解释和预测评级之间缺乏连贯性的问题,这将大大削弱系统的可信度。
贡献:(1) 开发了一种自动化评估rating-explanation一致性的方法 (2) 在PETER的基础上提出了一个新的可解释推荐系统,以自然语言生成个性化和一致的解释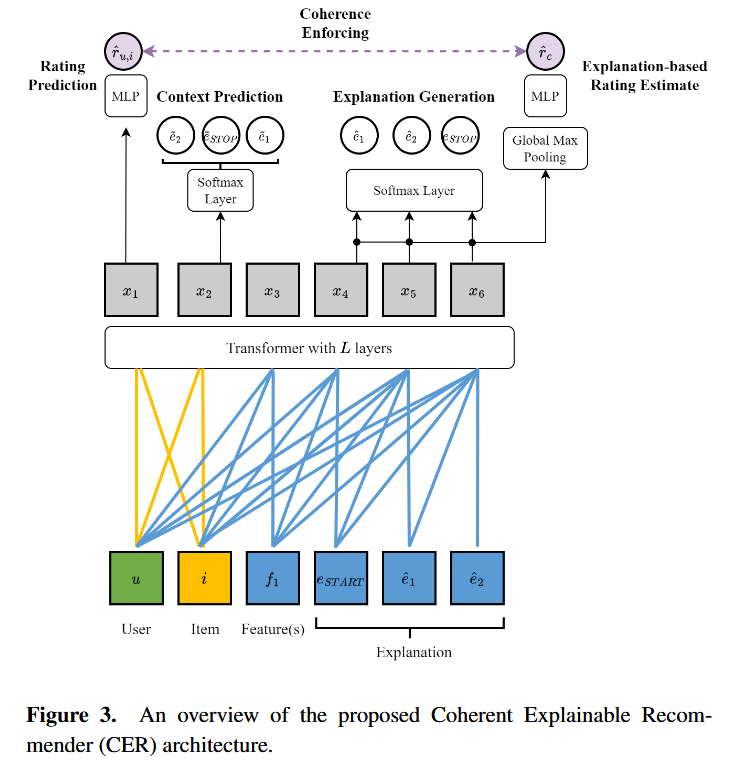
评估方法:首先人工采集、注释rating-explanation数据,然后进行二元分类训练作为一致性评估器
缺陷:(1) CER使用Transformer作为backbone,这限制了生成性能 (2) CER对生成解释的评分估计依赖于预训练词嵌入的最大池化,这无法捕获丰富的上下文信息Coherency Improved Explainable Recommendation via Large Language Model (CIER)
Challenge:目前的可解释推荐工作采用多任务学习的模式,通过共享隐藏表示层但拥有独立的输出层。这种训练方式会产生不一致的解释。
创新: (1) 使用LLM作为主干模型来预测评级并生成解释 (2) 采用next-token prediction的方式来生成评级和解释
评估方法: 使用GPT4和预训练的情感分析模型来评估连贯性。