长序列用户建模
1. SIM模型
模型由GSU+ESU两部分组成:
通用搜索单元GSU: 从原始的任意长顺序行为数据中进行通用搜索,结合候选项的查询信息,得到与候选项相关的子用户行为序列
精确搜索单元ESU: 模拟候选项目与 SBS 之间的精确关系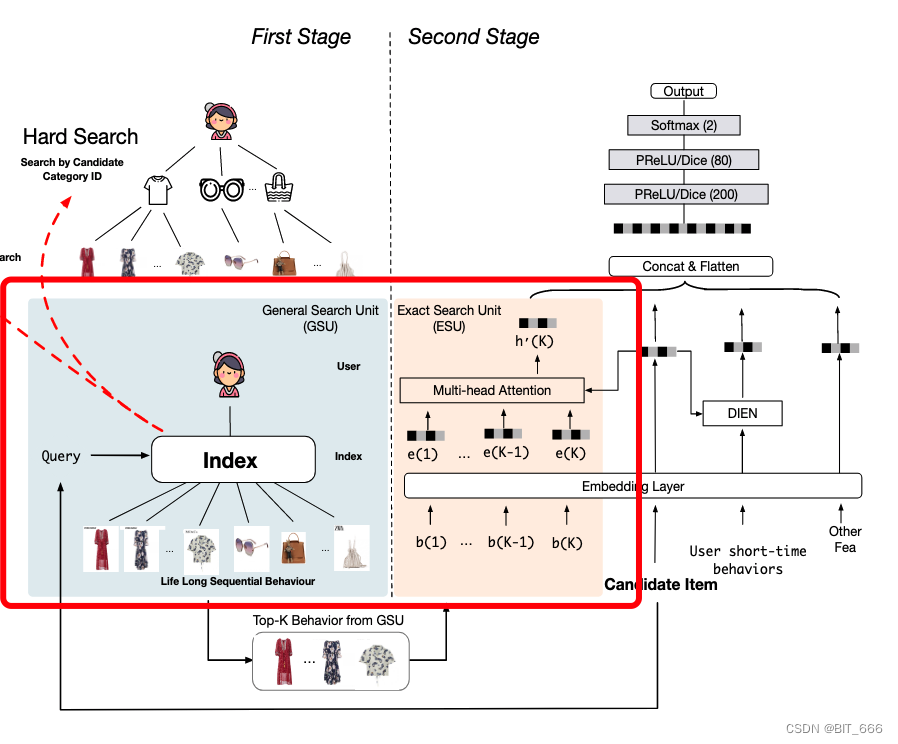
对于GSU部分,模型提出了两种通用搜索方案:硬搜索Hard Search 和 软搜索Soft Search
硬搜索Hard Search: 根据item_category或item_id对behavior分成若干group,只检索与target item相同的group
软搜索Soft Search: 其中$W_a$和$W_b$为可训练参数,基于长期行为数据的辅助 CTR 预测任务进行训练。训练完成后,行为表示为$U_r=\sum_{i=1}^Tr_i e_i$,然后对每个行为表示和目标向量取内积,取分数最高的 Top-K 作为后续模型子集(内积搜索采用ALSH方法, 迅速高效)
对于ESU部分,通过Target Attention获取检索子集中每个行为和target item之间的注意力,通过多头注意力的方式获得用户长期兴趣表示
小结:
SIM模型作为处理用户长序列用于兴趣建模的经典方案仍存在很多问题,例如:
- GSU的检索条件过于简单导致的信息丢失
- Optimization: 多场景,多行为等 Challenge: 对行为分组会破坏信息完整性
- 两阶段范式并非端到端模型,建模模型和预估模型目标很难保证强一致性,即GSU与ESU之间的gap
- Optimization: 将Target Attention直接应用到长期行为序列,将两阶段建模修改为端到端建模 Challenge:如何高效的对长序列进行聚合
- 依赖ID特征进新用户行为建模,缺乏对用户和商品的语义信息的理解
- Optimization: 使用LLM对用户行为进行建模 Challenge:(1)受LLM上下文长度的限制,无法直接有效的对lifelong behavior进行建模 (2)LLM很难关注序列中的时间信息,对动态兴趣变化的感知较弱
(3)效率问题:随着输入行为序列长度的增加,训练和推理所需的时间会迅速增加
- Optimization: 使用LLM对用户行为进行建模 Challenge:(1)受LLM上下文长度的限制,无法直接有效的对lifelong behavior进行建模 (2)LLM很难关注序列中的时间信息,对动态兴趣变化的感知较弱
2. ETA: Efficient Long Sequential User Data Modeling for Click-Through Rate Prediction
论文链接:https://arxiv.org/abs/2209.12212
参考链接:https://mp.weixin.qq.com/s/yuM9ZRR91fMsC5eJBd1yLg
Optimization: 将Target Attention应用到长序列中,缓解GSU和ESU的gap。它通过改善内积计算的方式提高target attention的效率
ETA 首先通过 SimHash 算法为打分商品和用户历史行为生成 Hash 签名,之后通过 HanmingDistance 为每个从中挑选出最相似的 TopK 个behavior和对应的target item,最后再利用进行标准的 Target Attention。(Novelty: 两个二进制 Hash 签名的 HanmingDistance 的计算是两个两个二进制数的异或运算和异或结果 1 的计数,二进制的运算效率要远远高于两个浮点数向量的内积)
Locality-sensitive hashing (LSH)是一种高维向量空间快速检索 K 近邻的方法。通常两个向量越相似,则可以以越高的概率获得相同的hash映射。由于概率存在一定的误差,通过 Multi-Round LSH 进行多轮 Hash,即可减少误差,提升精准度。
Multi-Round LSH:两个向量可以在一个二分类的球面上多次旋转投影,越相似的向量在多次旋转投影中落到同一个分类面的概率就越大。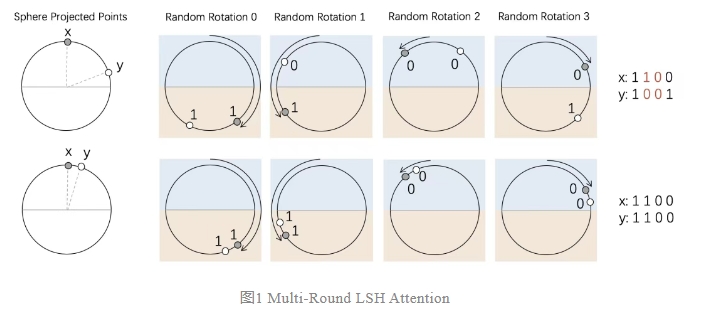
SimHash算法:对稠密向量的每一维计算m次二进制hash,拼接起来作为该向量的SimHash结果
下面给出ETA的框架图:
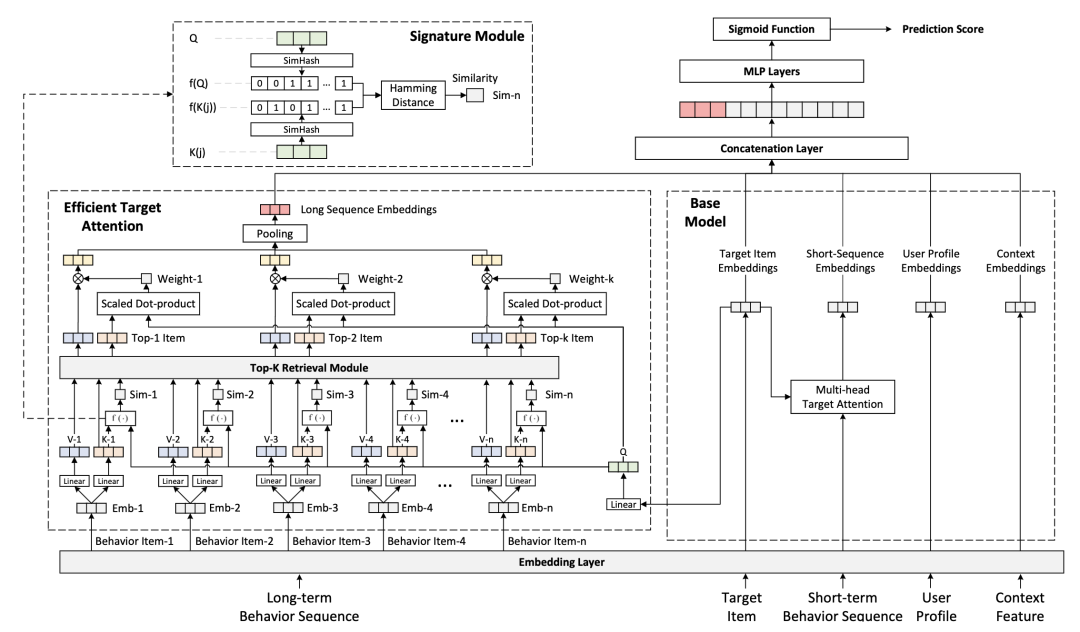
3. TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou
参考链接:https://mp.weixin.qq.com/s/DjzXpc-9oenmEKSXEJ74Qw
Optimization: 将Target Attention应用到长序列中,缓解GSU和ESU的gap。他通过改善Attention计算中的线性映射来对target attention进行加速
具体来说,TWIN将用户行为特征分为固有特征和交互特征,其中固有特征仍然按照$KQ^T/ \sqrt{d}$的方式计算注意力分数,其中$K_h W_h$是缓存起来的,直接查表获得;而Q的计算与序列长度无关,计算量不大;对于交互特征$K_c$, 直接使用维度较低的变换矩阵得到注意力分数
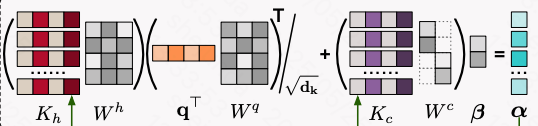
TWIN框架图: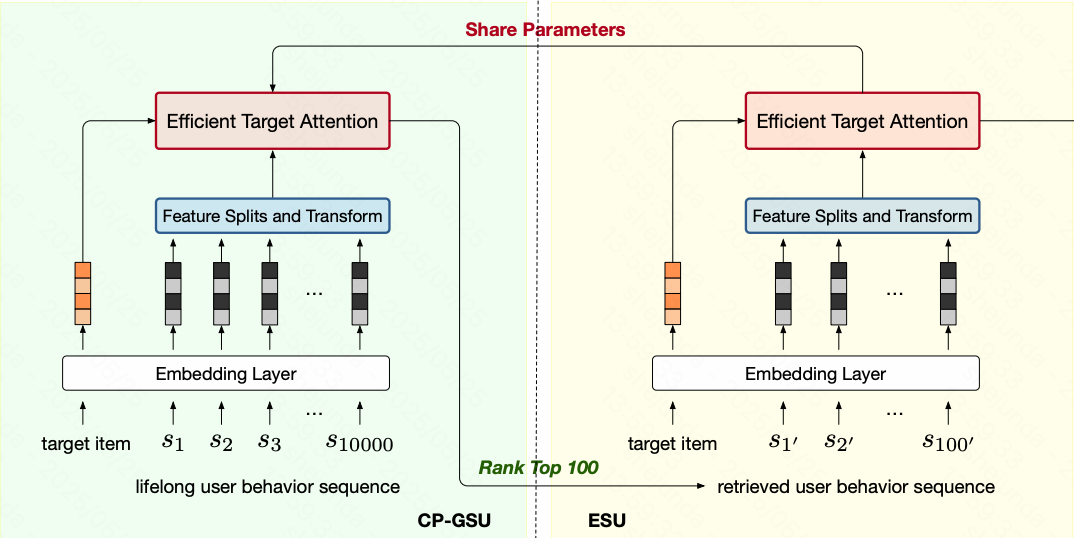
4. TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou
参考链接:https://zhuanlan.zhihu.com/p/747198544
Optimization: 在TWIN工作的基础上,根据简单规则对长序列进行分组,再在每个组内进行层次聚类得到簇,用于降低序列长度(可以处理更长的用户序列)
需要注意的是,v2版本中的Target Attention的实现基本和TWIN类似, 但需要把原来的Item部分换成聚类。
TWIN-v2框架图: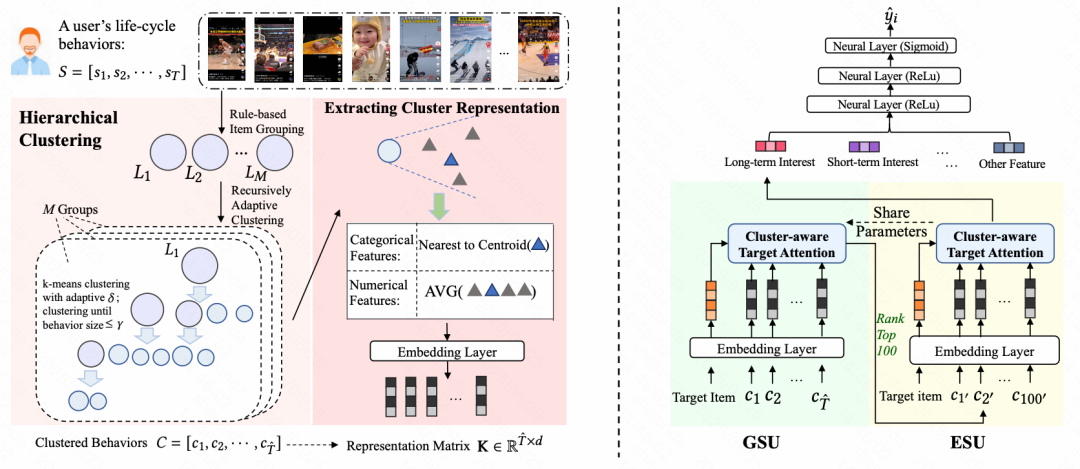
5. LREA: Efficient Long Sequential Low-rank Adaptive Attention for Click-through rate Prediction
论文链接:https://arxiv.org/pdf/2503.02542
参考链接:https://mp.weixin.qq.com/s/D_T5w7bF5DGn1m8VUfie4w
MLA参考链接:https://www.cnblogs.com/zrq96/p/18732985
Optimization: 利用低秩矩阵分解来简化Target Attention计算
首先回顾下计算Target Attention的时间复杂度,将Target Item视为Q,用户行为序列视为K和V。记L为序列长度,B为target item个数,d为稠密向量维度。用户行为序列表示为$E_s \in R^{L \times d}$,target item表示为$E_t \in R^{1 \times d}$
$$ TA(E_s,E_t) = E_s^T \odot AttScore(E_s, E_t) $$
其中,$E_s^T \in R^{d \times L}$, $AttScore(E_s, E_t) \in R^{L \times B}$.所以Target Attention在线上推理时的时间复杂度为O(LBd)
关于模型中低秩矩阵的实现,由于数学过程有些繁杂,这里不再展开,它的功效在于计算target attention时,每个部分能够以低秩矩阵的形式参与计算,时间复杂度变成O(Brd)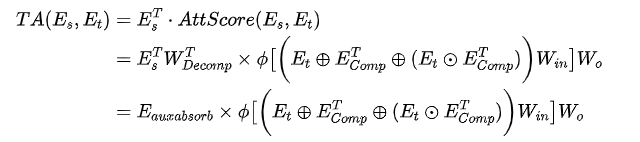
LREA框架图: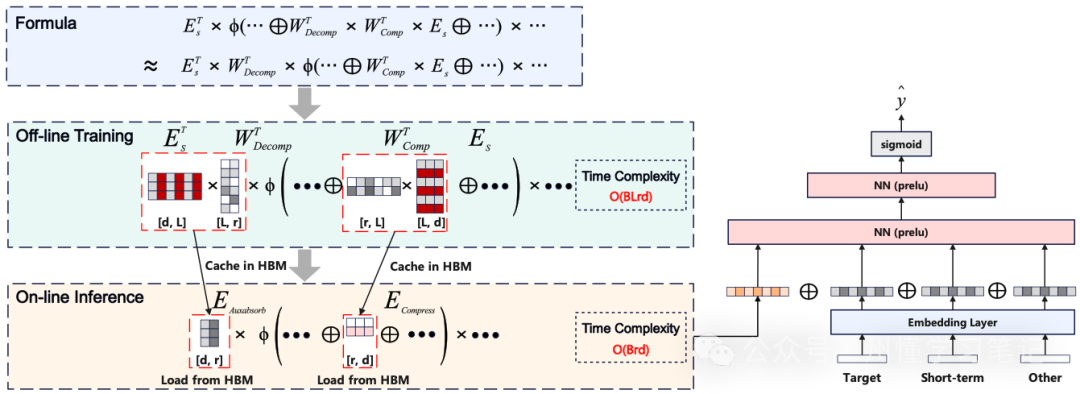
6. LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders
论文链接:https://www.arxiv.org/pdf/2505.04421
参考链接:https://mp.weixin.qq.com/s/c0dbmF1PdhJOcffRXzzS0Q
Optimization: 不依赖中间阶段(GSU),直接长序列建模。通过对tokens按时间顺序聚合,使用Cross Attention压缩长序列的方式来降低计算开销
作者设计了一个全局token放在序列开头,一方面用来稳定长序列的注意力机制,另一方面作为全局信息通过聚合整个上下文信号来影响其他token
Tokens聚合: 作者将用户行为长序列按时间顺序每K个Item合并成一组, 这样合并后的序列长度则减少为$\frac{L}{K}$。相关效率分析可见参考链接
Cross Attention: 作者从原始的长序列$H$中采样出$H_s$子序列作为部分Query序列,实验发现,直接使用最近的k个交互作为部分Query序列的策略效果最好。然后, 再在前面拼接Global Tokens的表征就得到最终的Query矩阵$O=[G;H_s] \in R^{(m+k) \times d}$。 cross attention的具体计算如下: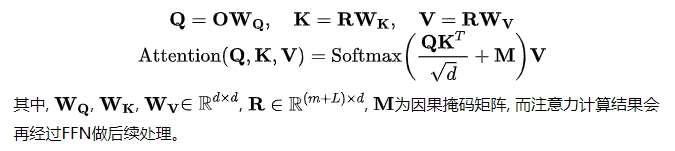
LONGER框架图: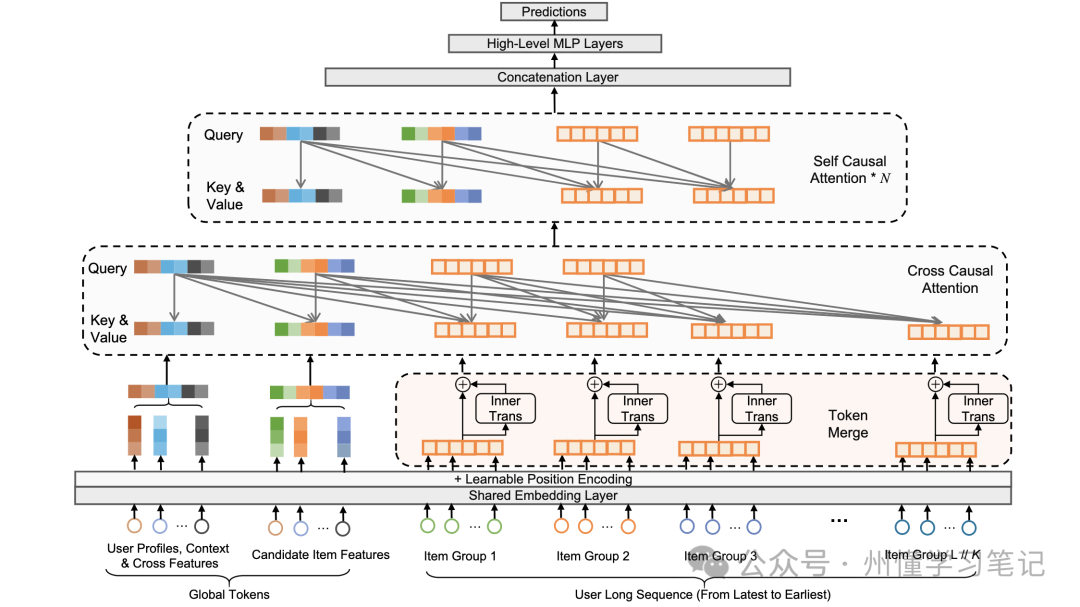
7. DGIN: Deep Group Interest Network on Full Lifelong User Behaviors for CTR Prediction
Optimization: 不依赖中间阶段,将完整的终身行为序列分组,通过统计信息和聚类特征分析组内行为,以捕获群体特征,用于确定用户兴趣。
DGIN由嵌入层、Group Module、Target Module和MLP组成。框架图如下所示: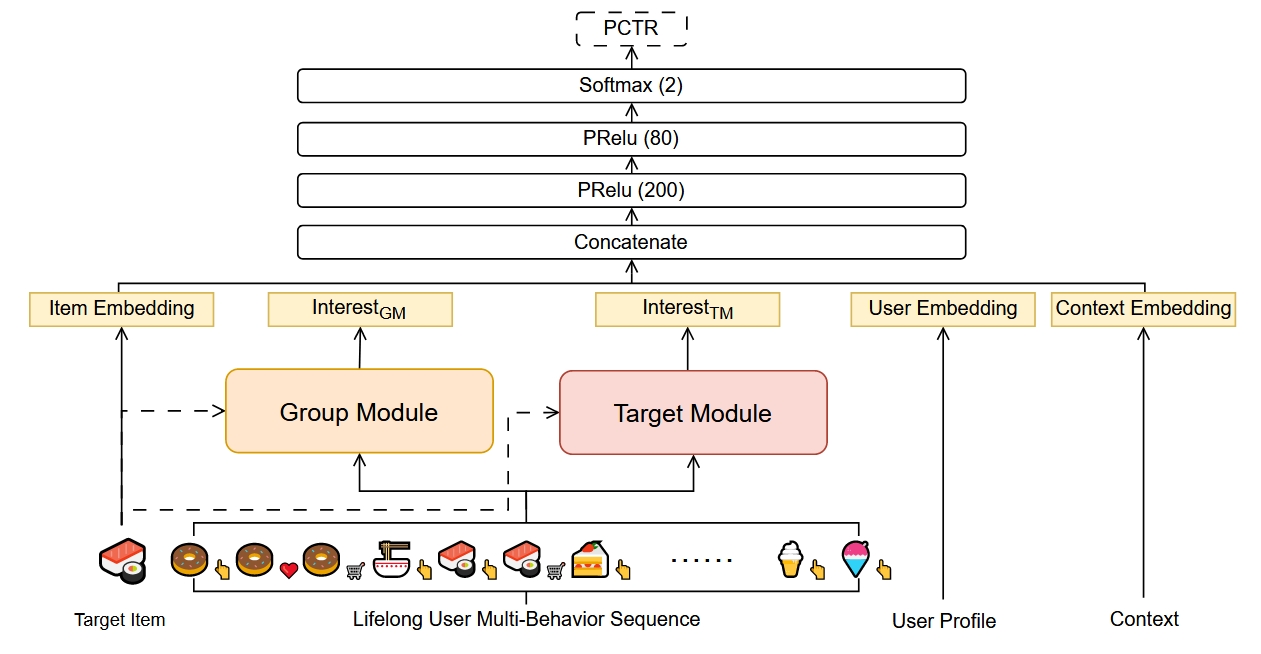
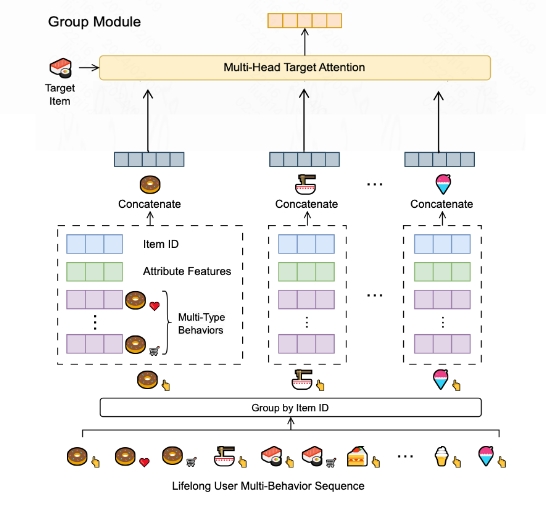
Group Module: 首先对lifelong behaviors根据interest key进行分组,论文中使用的是item_id(也可以使用category_id等)。为了弥补分组造成的信息损失,作者设计了两种类型的特征(statistical, aggregated)作为兴趣组的属性.统计属性是从不同角度对组内行为的统计,聚合属性是通过对原始行为的独特属性(如时间戳)进行Multi-Head-Self-Attention而获得的。
在收集了每个兴趣组的属性表示后,作者使用Mutli-Head-Target-Attention对属性特征和target item的嵌入表示进行融合,得到最终的兴趣表示
$$Interest_{GM}=MHTA(e^i, e_g), e_g=[e_{g_1}, e_{g_2}, …, e_{g_G}], e_{g_i}=[e_{attr_i}, e_{attr_s}, e_{attr_a}]$$
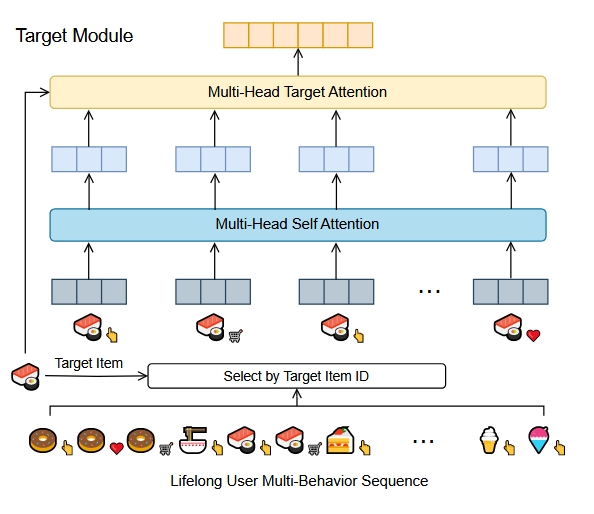
Target Module: Target Module的设计理念和SIM差不多,还是先根据interest key检索top-k获得子序列,然后对子序列中的行为和target item进行target attention。
个人的一点理解: Group Module是基于target item的group-level的粗粒度特征表示,Target Module是基于target item的组内behavior-level的细粒度特征表示
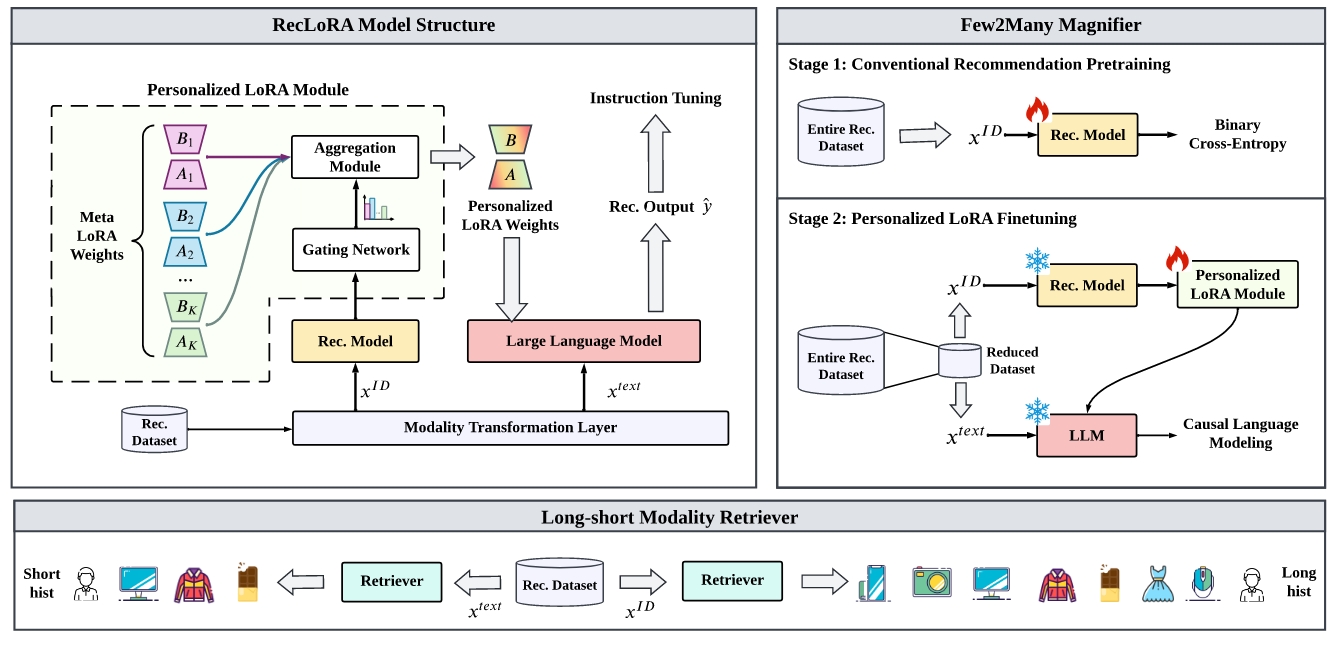
8. Lifelong Personalized Low-Rank Adaptation of Large Language Models for Recommendation
Optimization: 使用LLM来处理长序列用户兴趣建模,利用传统CRM实现Lora个性化
LLM用于用户兴趣建模的优势在于可以更好地利用元数据中的语义信息。但存在的挑战是训练效率和上下文长度的限制。此外,传统的基于LLM的推荐方法在个性化设计上主要考虑提示个性化或表示个性化,而RecLora将工作重心放到Lora个性化上,将长序列的处理转移到CRM本身,LLM并不扩展用户行为序列,由CRM的提供长序列用户表示来指导Meta Loras的个性化权重。
9. Hierarchical Tree Search-based User Lifelong Behavior Modeling on Large Language Model
Optimization: 使用LLM来处理长序列用户兴趣建模,并考虑了动态兴趣演变
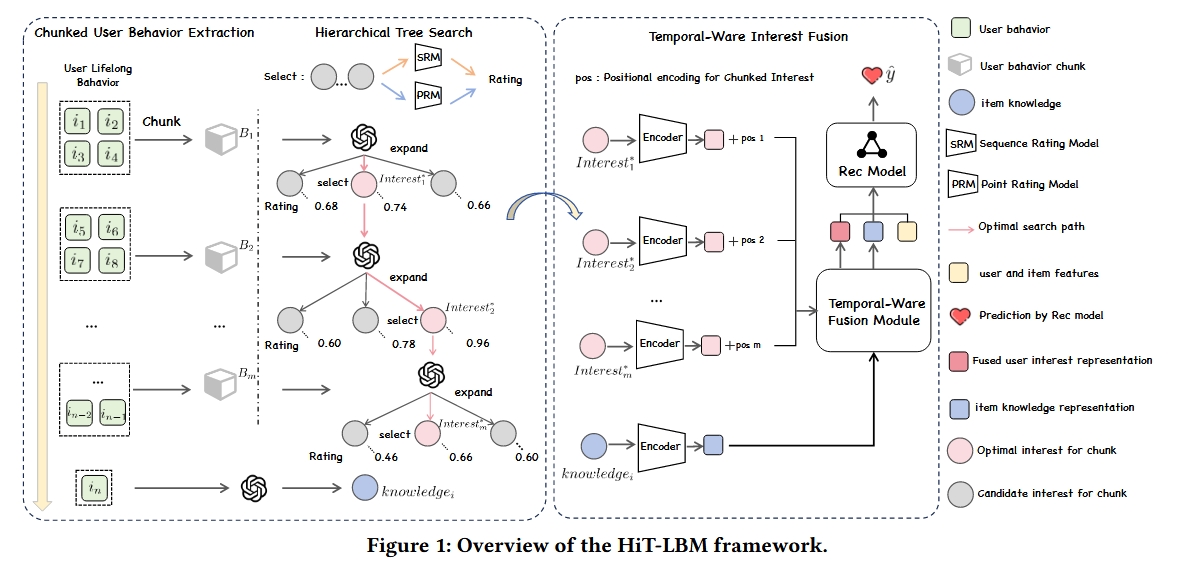
作者提出了一种基于分层树搜索的终身行为建模框架HiT-LBM,HiT-LBM 集成了分块用户行为提取(CUBE) 和分层树搜索兴趣(HTS),以捕获用户的多样化兴趣和兴趣演变
分块用户行为提取(CUBE): 考虑到LLM在处理长文本方面的局限性,CUBE将用户的lifelong behavior划分为大小合适的时间块。并允许LLM在相邻行为块之间以级联的方式动态的学习用户兴趣。
分层树搜索兴趣(HTS): 为了防止动态学习用户兴趣的过程中的错误累计,HITS设计了序列评级SRM和点评级PRM这两个scoring model,来评估当前兴趣的连续性和有效性。
动态兴趣融合(Fusion): 将来自不同 chunk 的用户兴趣进行整合,从而产生用户终身的兴趣表示