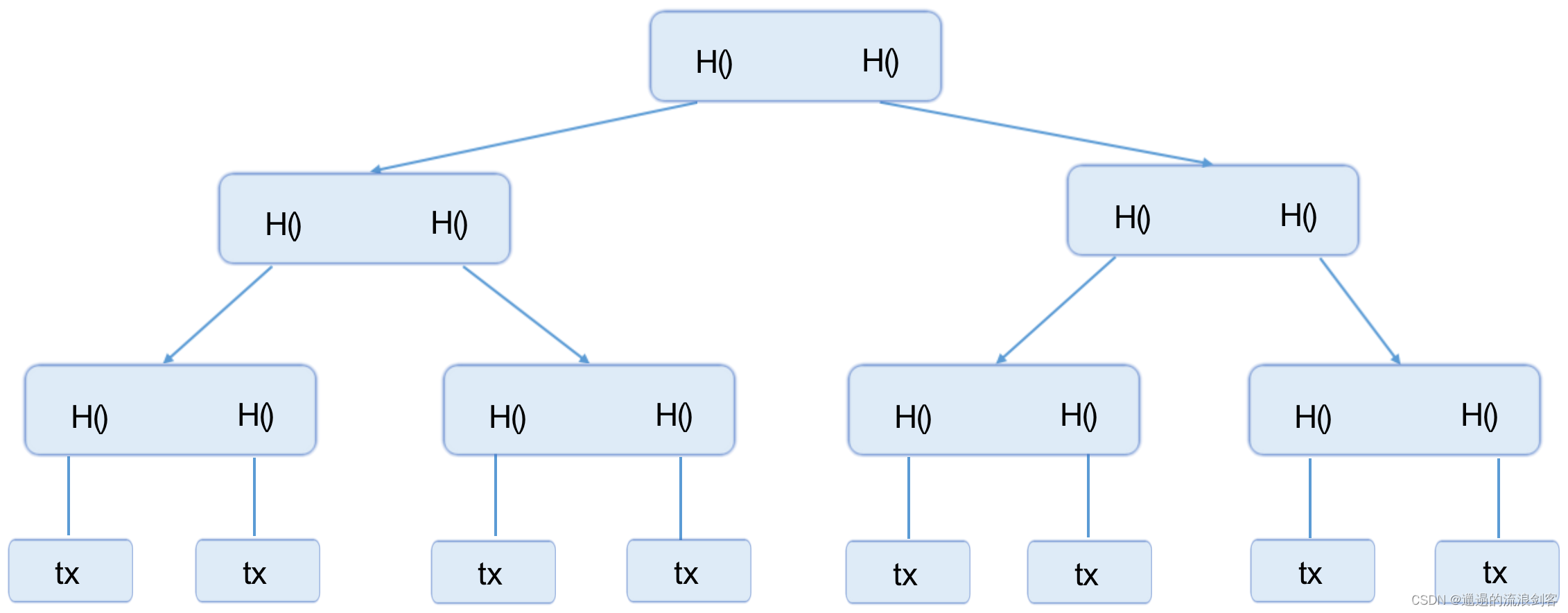
<BTC> 密码学原理,数据结构,协议,实现 写在前面:前段时间把b站上北大肖老师的区块链课程速通了一遍,这里引一下csdn上的优质课程笔记,便于个人后续温习。博客链接:https://blog.csdn.net/qq_40378034/category_11862943.html课程链接:https://www.bilibili.com/video/BV1Vt411X7JF/ 2025-05-01 #Web3
RLHF(三):基于TRL的GrpoTrainer详解 写在前面:目前主流的LLM post-training框架主要有trl, OpenRLHF, verl。后两者集成度较高,适合对LLM零代码训练,而trl灵活性较强,这里主要对GRPO Trainer的训练流程进行梳理 2025-04-19 #LLM #RLHF
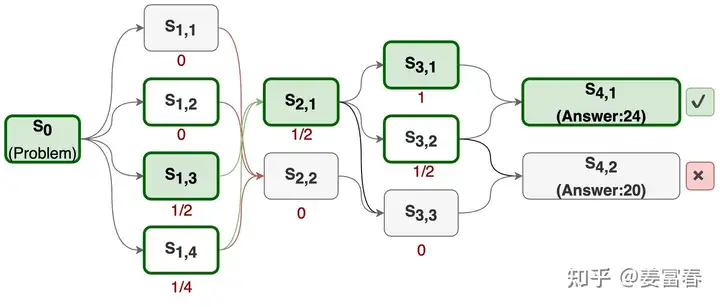
RLHF(二):偏好数据采集 ORM 和 PRMORM:结果奖励模型,是不管推理有多少步,对完整的生成结果进行一次打分,是一个反馈更稀疏的奖励模型PRM:过程奖励模型,是在生成过程中,分步骤,对每一步进行打分,是更细粒度的奖励模型 使用PRM可以在post-training和inference两个阶段提升模型的推理性能: Post-Training阶段:在偏好对齐阶段,通过在RL过程中增加PRM,对采样的结果按步骤输出奖励值 2025-04-18 #LLM #RLHF
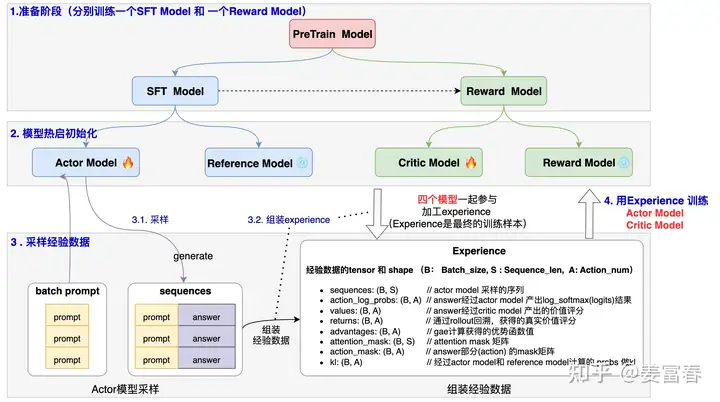
RLHF(一):LLM post-training 1. PPO算法$L_{PPO} = \sum_{(s_t,a_t)}\frac{\pi_\theta(a_t|s_t)}{\pi_{ref}(a_t|s_t)}A(s_t,a_t) - \beta KL(\pi_\theta, \pi_{ref})$ PPO的训练步骤如下:(1)收集人类反馈,人工标注数据 (2)训练奖励模型 (3)采用PPO强化学习,优化策略 在LLM上使用PPO算法 2025-04-17 #LLM #RLHF
Syncthing安装 下载安装1234567# 1、下载最新部署包curl -s https://api.github.com/repos/syncthing/syncthing/releases/latest | grep browser_download_url | grep linux-amd64 | cut -d '"' -f 4 | wget -qi -# 2、解压并安装tar 2025-03-25 #Tool
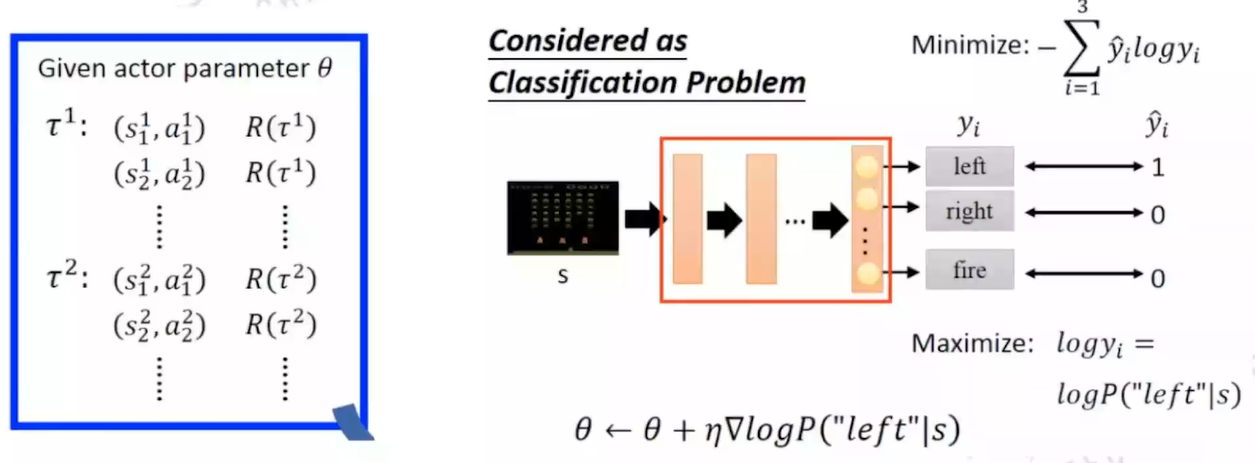
强化学习系列(五):Policy Gradient 写在前面:前面所提到的Q-value Based方法无法解决连续动作空间场景下的优化问题,因为Q-learning的策略是从多个离散动作中贪婪地选择最大Q值,在连续空间中,无法枚举所有动作。为此,本节讲述一种直接面向策略的优化方法:Policy Gradient 2025-03-15 #AI #Algorithm
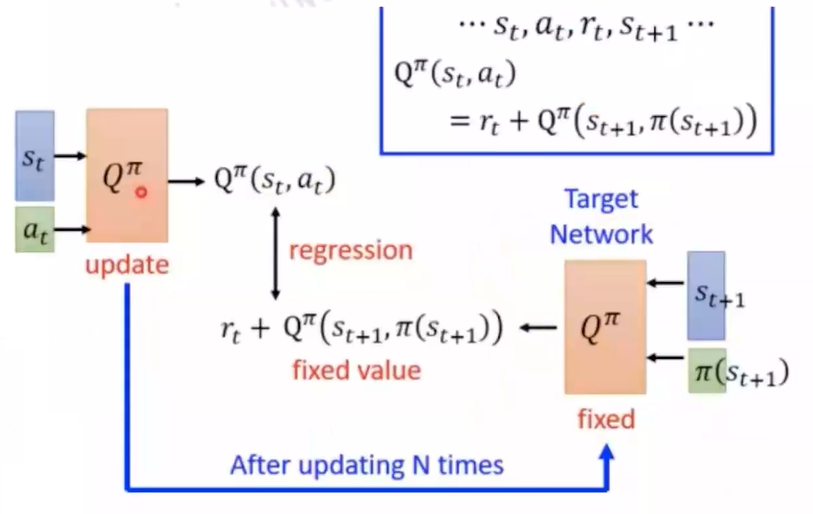
强化学习系列(四):DQN算法 写在前面:前面讲解了在On-Policy和Off-Policy环境下如何进行策略提升的几种常用方法,但是在实际应用场景中,state的数量可能是非常庞大的,为了存储每个state-action pair所需要的lookup-table所需要的空间会很庞大,无法通过遍历的方式去evaluate每个state-action pair。这就需要我们考虑如何对Q,V进行建模,通过函数逼近的方法估计连续空间 2025-03-14 #AI #Algorithm
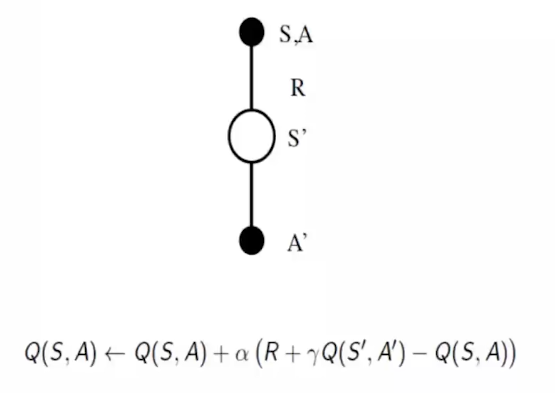
强化学习系列(三):Model-Free Control 写在前面:系列二中提及的MC/TD方法都是在已知策略$\pi$的前提下,估计每个状态的期望回报。前者是等到整个回合结束利用完整回报$G_t$来更新价值函数,后者利用一步预测和当前奖励动态更新价值函数。可以看到的是,这些方法知识学习了价值函数,并没有改变策略。在这一节,我们主要介绍一些常用的策略优化方法。 2025-03-12 #AI #Algorithm
Lora Adapter调试跟踪 打算花点时间看看在peft库中lora是怎么注入base model的,这里简单总结下: 首先写个测试程序: 123456789101112131415161718192021import torchfrom peft import LoraModel, LoraConfigfrom transformers import AutoModelForCausalLM, AutoTokenizermo 2025-03-11 #Code #debug
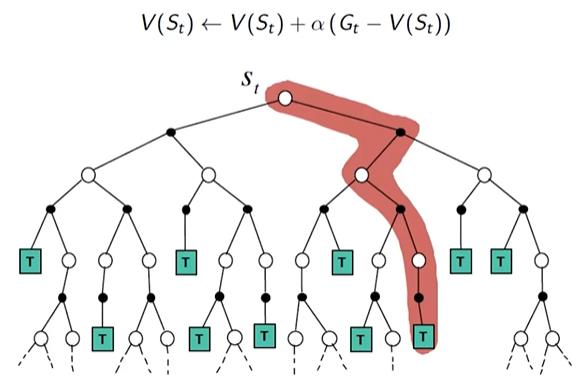
强化学习系列(二):Model-free Prediction 写在前面: Prediction任务是用来在给定策略$\pi$的前提下,基于价值函数和奖励函数来评估该策略的好坏。Control任务用来对策略进行提升和改进。根据是否已知状态转移矩阵(MDP transition)分为Model-Based Prediction和Model-free Prediction 2025-03-08 #AI #Algorithm